The upcoming Veeam Availability Suite v9, among many new and exciting features, will bring more enhancements for Enterprise environments. In these environments, two main characteristics usually arise, and require proper solutions: scalability and management of multiple remote/branch offices.
Interaction with guest OS of the protected virtual machines for proper backup and restore is a great advanced capability of our software. Being a completely agentless solution, our backup jobs deploy a temporary, runtime process into every virtual machine for which “Application Aware Image Processing” is enabled. This process is responsible for VSS processing orchestration, performing application-specific backup steps such as log truncation, and guest file system indexing.
Before v9, all the guest interactions were performed by the backup server. For each protected VM, the central console deployed the guest interaction process directly into the VM (either directly into the guest OS via network, or using VIX API via a host connection for guests on disconnected networks). This has always worked perfectly, but as protected environments grew in size and complexity, two limits became apparent.
First, scalability. Guest processing is managed by the backup server, but the amount of protected VMs in a typical customer environment has grown so significantly over time, that backup server resources started to become a bottleneck – limiting the amount of concurrent guest interactions possible before jobs would start experiencing timeouts.
The second limit is somewhat related to the first. Enterprise environments usually also have several remote offices, with virtualized environments deployed locally to serve users of those branch offices. Since in such scenarios, the VBR server is typically deployed at the headquarters, all guest interactions have to occur over WAN link, which is often slow.
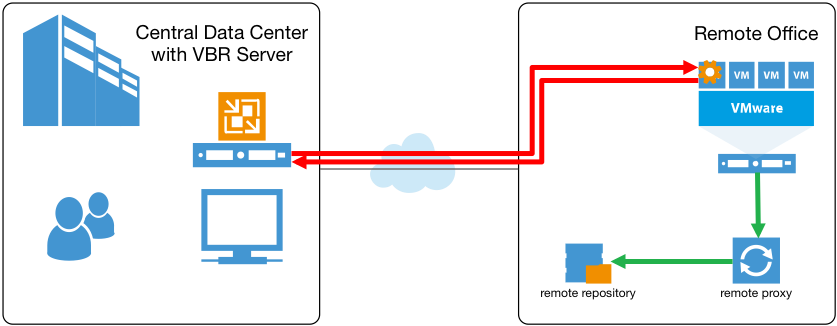
So, even if both a remote proxy and repository were deployed at the branch office to keep backup and restore traffic local, the guest interaction traffic still needed to cross WAN, which resulted in scalability issues for such environments.
To improve performance, v9 will introduce a Guest Interaction Proxy. Customers can assign this virtual role to any managed Windows server (including existing backup proxies and repositories). The remote backup proxy in a branch office is usually the ideal candidate, as it’s the closest one to the virtual machines it protects:
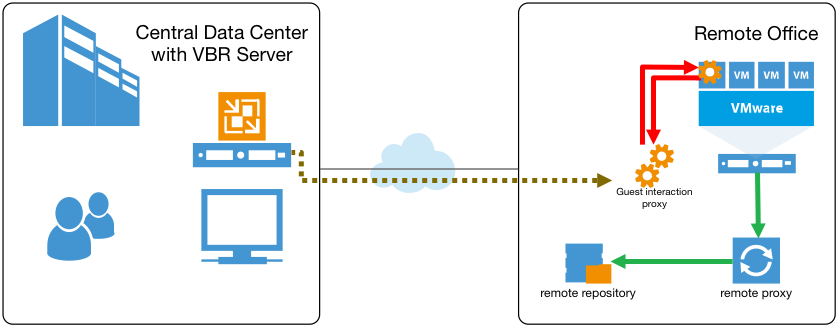
With the Guest Interaction Proxy in place, the backup server will only send control commands over the WAN link. It will be the “local” Guest Interaction Proxy that will upload the guest interaction process to the processed VMs. As a result, traffic crossing the slow link will be minimized, while the load on the VBR server will be reduced. And since a single backup server will be able to control multiple Guest Interaction Proxies, scalability is improved tremendously. For example, think about an Enterprise user with 500 remote sites. Now, this business can designate every site’s backup proxy to also act as the Guest Interaction Proxy, all controlled by the central backup server. And obviously, multiple guest interaction proxies can also be used within a single large datacenter to improve the performance and scale of guest interaction activities.
Another hidden benefit of this functionality that may not be immediately obvious, is getting access into the guest OS when networkless processing via VIX is not possible – for example, when the required high-privilege guest interaction account cannot be provided due to security considerations. Basically, you can now designate a Windows computer with NICs in both production and backup networks, and leverage that as a guest interaction proxy to “forward” communication from the backup network into the production network.
But backups are always just half of the story. Once data is safely stored in a repository, a restore may be necessary. And, if once again we look at this from the remote office scenario, today, file level restores have to be driven by the central backup server, with backup files mounted directly on it:
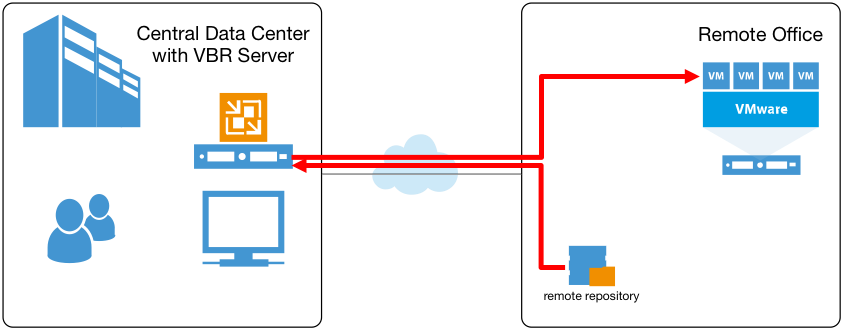
So, even if the backup repository itself was “local” to the remote virtualized environment, during in-place file level restores the data has to cross the slow WAN link twice — first to be pulled to the backup server, and then sent back to the virtual machine in the remote site. A popular workaround to this has been using Multi-OS File Level Restore (FLR) wizard with FLR helper appliance launched at the remote site, however this approach has its own drawbacks.
With v9, this is no longer necessary thanks to a new Mount Server setting for every backup repository. Basically, any Windows server managed by Veeam can now be designated as an FLR mount point for Veeam backups. And of course, there is no better choice for a remote office than an already existing Windows-based repository being a mount host for itself!

Now, thanks to this new component, the central VBR server will only send control commands over the WAN link, while the remote backup will be mounted by the designated “local” mount server for restoring the required files directly into the remote virtual machine, with all data transfers remaining within the remote site.
While we are talking “remote” operations, another very important addition that will come in v9 is a standalone console. Yes, we are talking about the long-awaited Veeam Backup & Replication console that Veeam administrators will be able to install separately from the backup server, for example on their own workstation, enabling the management of the backup server remotely over the network. Say good-bye to RDP sessions or with multiple users kicking out each other while connecting to the same backup server, as each operator will now be able to have their own console. Notably, the console also assumes the role of a mount server for advanced recovery scenarios that require backups to be mounted locally (such as for Veeam Explorers), a capability that will be very helpful in ROBO scenarios.
But, that’s not all for today! As you could see already from v8, we are fully committed to delivering the best tape support on the market for any customer size – and v9 will be bringing multiple additional tape functionality enhancements that our enterprise clients have been dying to get. I will only cover the top few, but I can assure you there are many more smaller improvements!
First, and the biggest one if you ask me, is an ability to create a Media Pool detached from a single physical library and able to span data across multiple libraries. This “global media pool” will become the main target when it comes to tape jobs and it will improve both performance and the overall management experience.

A tape job pointed to the “global media pool” can use multiple libraries or standalone drives according to the configured library failover order and switch to one of the available libraries if any failover event happens. For example, imagine if one library runs out of free media, or has all tape drives occupied. Thanks to global media pools, a tape job can now switch to another library with free media or tape drives still available.
What other great features are we adding to tape operational performance? The much requested parallel processing between multiple tape drives becomes available in v9! What previously required setting up multiple media pools and tape backup jobs, thus increasing complexity, is now available out of the box!

Next, let’s talk about tape media rotation. I am sure that many of you will be happy to hear that a new type of media pool will be available in v9: the dedicated GFS Media Pool for full backups. Again, while it was possible to achieve largely the same result with multiple media pools in v8, v9 takes it one step further by completely removing the associated management complexity.
If you are familiar with our existing backup copy job’s Grandfather – Father – Son (GFS) rotation mechanism from v8 – the concept remains the same here, so it should be pretty easy to understand. When the full backups are targeted to the GFS Media Pool in the backup to tape job settings, the corresponding tapes will be retained according to a specified retention scheme, involving weeks, months, quarters, and even years – as long as your data retention policy requires.
With a GFS media pool, fewer tapes are required to obtain a longer retention. For example, GFS rotation scheme configured to maintain 5 years of full backups will require only 20 tapes: 4 weekly, 12 monthly and 4 yearly tapes. Simple media pool is still available for shorter-term full backup retention and incremental backups, so you ultimately decide which media pool best covers the desired data retention scenario.
As you can see just from this blog post alone, there are a number of significant enterprise-specific functionality enhancements coming in v9. And trust me, we are only just starting with the announcements – as the coolest v9 enterprise functionality is yet to be disclosed. I hope our efforts clearly demonstrate that we do pay close attention to the unique needs of our enterprise customers, and are determined to provide you with a product that is 100% enterprise-ready, and can easily scale to maintain availability of your growing business.
Veeam Availability Suite v9 page
Upcoming webinar on these Enterprise Enhancements in v9 (Aug 20)