Parmi de nombreuses nouvelles fonctionnalités passionnantes, la prochaine Veeam Availability Suite v9 apportera plus d’améliorations pour les environnements des grandes entreprises. Dans ces environnements, deux caractéristiques principales se distinguent habituellement et nécessitent des solutions appropriées : l’évolutivité et l’administration de plusieurs filiales ou sites distants.
L’interaction avec l’OS invité des machines virtuelles protégées pour une sauvegarde et une restauration appropriées constitue une fonctionnalité avancée et particulièrement utile de notre logiciel. Notre solution étant entièrement sans agent, nos tâches de sauvegarde déploient un « runtime process » éphémère sur chaque machine virtuelle pour laquelle l’AAIP (Application-Aware Image Processing) est activé. Ce processus est responsable de l’orchestration des traitements VSS et effectue des tâches spécifiques aux applications concernées telles que la troncature des journaux de transactions ou l’indexation des fichiers de Guest OS.
Avant la v9, toutes les interactions avec le Guest OS étaient effectuées par le serveur de sauvegarde. Pour chaque VM protégée, la console centrale déployait le « runtime process » directement dans la VM (soit par l’intermédiaire du réseau, soit en utilisant les APIs VIX en l’absence de connexion réseau à la VM). Cela a toujours parfaitement fonctionné, mais au fil de la croissance des environnements protégés en taille et en complexité, deux limites sont devenues apparentes.
Tout d’abord, l’évolutivité. Le traitement AAIP (Application-Aware Image Processing) des Guest OS est orchestré par le serveur de sauvegarde, mais le nombre de VMs protégées dans un environnement client typique est devenue si élevé avec le temps que les ressources de serveur de sauvegarde ont commencé à constituer un goulot d’étranglement qui limite le nombre possible d’interactions simultanées avec le Guest OS.
La seconde limite est en quelque sorte liée à la première. Les environnements des grandes entreprises comportent en règle générale plusieurs sites distants, avec des environnements virtualisés déployés de manière locale pour servir les utilisateurs de ces filiales. Comme dans de tels scénarios le serveur VBR est généralement déployé au siège, toutes les interactions avec l’OS invité doivent se produire par l’intermédiaire de la liaison WAN, ce qui s’avère souvent lent.
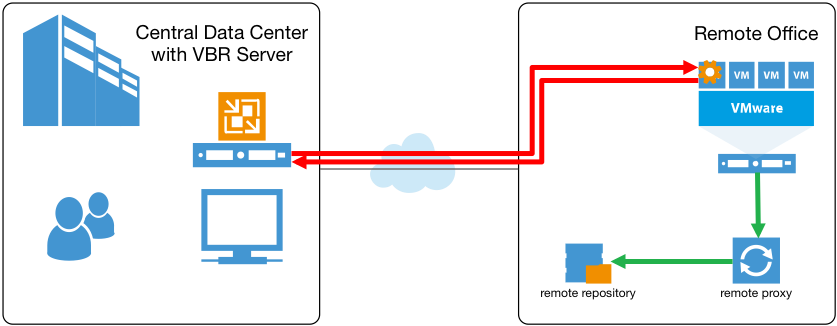
Ainsi, même si un proxy et un repository distants étaient déployés sur le site de la filiale pour maintenir le trafic de sauvegarde et de restauration au niveau local, le trafic des interactions avec l’OS invité devait encore traverser le WAN, ce qui générait des problèmes d’évolutivité pour ces environnements.
Pour améliorer le niveau de performance, la v9 introduira le proxy d’interaction Guest OS. Les clients pourront assigner ce rôle virtuel à tout serveur Windows administré (y compris les proxys et repositorys de sauvegarde existants). Le proxy de sauvegarde distant d’une filiale est habituellement le candidat idéal pour cela, car c’est le plus proche des machines virtuelles qu’il protège :
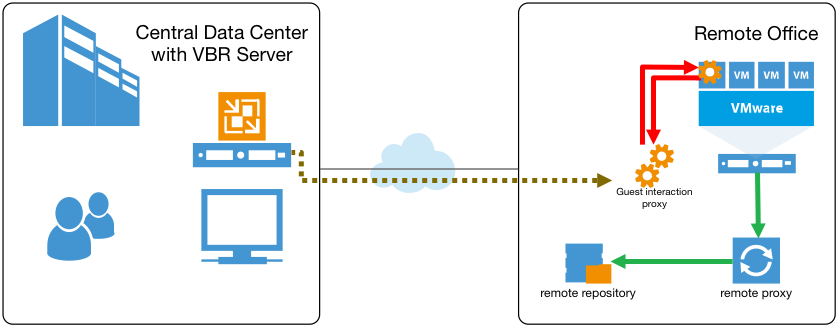
Avec le proxy d’interaction Guest OS en place, le serveur de sauvegarde ne fera qu’envoyer des commandes de contrôle par l’intermédiaire de la liaison WAN. Ce sera le proxy d’interaction Guest OS « local » qui téléchargera le « runtime process » vers les VMs traitées. En conséquence, le trafic passant par la liaison lente sera minimisé, tandis que la charge du serveur VBR sera réduite. Et comme un unique serveur de sauvegarde sera capable de contrôler plusieurs proxys d’interaction avec l’OS invité, l’évolutivité sera améliorée de manière considérable. Par exemple, pensez à un utilisateur de niveau entreprise avec 500 sites distants. Cette entreprise peut paramétrer le proxy de sauvegarde de chaque site pour agir également en tant que proxy d’interaction avec l’OS invité, et tous seront contrôlés par le serveur de sauvegarde central. Et évidemment, plusieurs proxys d’interaction avec l’OS invité pourront aussi être utilisés dans le cadre d’un grand data center pour améliorer les performances et l’évolutivité des activités d’interaction.
Un autre avantage caché de cette fonctionnalité qui n’est pas immédiatement évident est d’obtenir l’accès à l’OS invité lorsque le traitement sans réseau via VIX n’est pas possible. Par exemple, quand le compte à hauts privilèges d’interaction avec l’OS invité nécessaire ne peut être fourni en raison de considérations de sécurité. En fait, vous pouvez désormais désigner un ordinateur Windows avec NICs dans les réseaux de production et de sauvegarde, et en tirer parti en tant que proxy d’interaction avec l’OS invité pour « transférer » les communications depuis le réseau de sauvegarde vers le réseau de production.
Mais les sauvegardes ne sont jamais que la moitié de l’histoire. Une fois que les données sont stockées de manière sûre dans un repository, une restauration peut s’avérer nécessaire. Et si nous regardons une fois encore depuis l’angle du site distant, aujourd’hui, les restaurations de niveau fichier doivent être effectuées par le serveur de sauvegarde central, sur lequel les fichiers de sauvegarde sont directement montés :
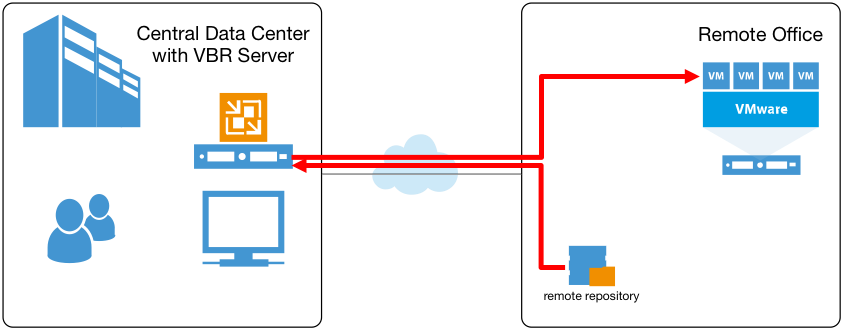
Ainsi, même si le repository de sauvegarde lui-même était « local » par rapport à l’environnement virtualisé distant, pendant les restaurations de niveau fichier à l’emplacement d’origine, les données doivent passer deux fois par la liaison WAN : la première pour être acheminée vers le serveur de sauvegarde, la seconde pour être renvoyées vers la machine virtuelle du site distant. Une solution de contournement répandue consiste à utiliser un assistant de restauration de niveau fichier (FLR) multi-OS avec appliance auxiliaire lancée sur le site distant. Toutefois, cette approche a ses propres inconvénients.
Avec la v9, ce n’est plus nécessaire grâce à un nouveau paramètre de serveur de montage pour chaque repository de sauvegarde. En fait, tout serveur Windows administré par Veeam peut désormais être désigné en tant que point de montage FLR pour les sauvegardes Veeam. Et bien sûr, il n’y a pas de meilleur choix pour un site distant qu’un repository Windows déjà existant jouant lui-même le rôle d’hôte de montage!

Maintenant, grâce à ce nouveau rôle virtuel, le serveur VBR central enverra uniquement des commandes de contrôle sur la liaison WAN, tandis que la sauvegarde distante sera montée par le serveur de montage « local » désigné pour restaurer les fichiers nécessaires directement sur la machine virtuelle distante, avec tous les transferts de données restant dans les limites du site distant.
Tant que nous parlons d’opérations « distantes », un nouvel élément très important à venir dans la v9 est la console autonome. Oui, nous parlons bien de la console Veeam Backup & Replication tant attendue que les administrateurs Veeam pourront installer séparément de leur serveur de sauvegarde, par exemple sur leur propre station de travail, et qui permettra l’administration du serveur de sauvegarde à distance à travers le réseau. Vous pouvez dire « au revoir » aux sessions RDP ou aux utilisateurs multiples qui se chassent les uns les autres en se connectant au même serveur de sauvegarde, car chaque opérateur pourra désormais disposer de sa propre console. Notamment, la console assume aussi le rôle de serveur de montage dans les scénarios de restauration avancés nécessitant le montage local des sauvegardes (tels que les Veeam Explorers), une fonctionnalité qui s’avérera très utile dans les scénarios ROBO.
Mais ce n’est pas tout pour aujourd’hui ! Comme vous avez déjà pu le voir dans la v8, nous nous employons pleinement à vous fournir la meilleure prise en charge de bandes du marché indépendamment de la taille de votre entreprise – et la v9 apportera de nombreuses améliorations supplémentaires à ce sujet que nos clients entreprise ont toujours voulu avoir. J’aborderai seulement les principales, mais je peux vous assurer qu’il y a beaucoup plus d’améliorations mineures !
D’abord, et c’est la plus importante de toutes, il y a la possibilité de créer un pool de supports détaché d’une seule bibliothèque physique et capable de s’étendre sur plusieurs bibliothèques. Ce « pool de supports global » deviendra la cible principale des tâches de sauvegarde sur bande et permettra d’améliorer les performances ainsi que l’expérience administrative dans son ensemble.

Une tâche de sauvegarde sur bande pointant vers le « pool de supports global » pourra utiliser plusieurs bibliothèques ou lecteurs autonomes selon l’ordre de basculement configuré pour les bibliothèques et basculer vers une des bibliothèques disponibles si un événement de basculement se produit. Par exemple, imaginez qu’une bibliothèque n’ait plus de supports vides ou que tous les lecteurs de bandes soient occupés. Grâce aux pools de supports globaux, une tâche de sauvegarde sur bande pourra désormais basculer vers une autre bibliothèque disposant de supports ou de lecteurs utilisables.
Quelles autres fonctionnalités exceptionnelles ajoutons-nous en ce qui concerne la performance opérationnelle des bandes ? Le traitement parallèle entre plusieurs lecteurs de bande tant demandé est une réalité avec la v9! Ce qui nécessitait auparavant de configurer plusieurs pools de supports et tâches de sauvegarde sur bande (augmentant ainsi la complexité) est désormais disponible dès l’installation!

Ce sera une option simple mais puissante qui vous permettra d’exécuter des tâches de sauvegarde sur bande pointant simultanément vers le même pool de supports ou de répartir l’archivage des fichiers de sauvegarde sources entre plusieurs lecteurs.
Ensuite, parlons de la rotation des bandes. Je suis sûr que nombre d’entre vous seront heureux d’apprendre qu’un nouveau type de pool de supports sera disponible dans la v9 : le pool de supports GFS dédié pour les sauvegardes complètes. Encore une fois, alors qu’il était possible d’aboutir largement au même résultat avec plusieurs pools de supports dans la v8, la v9 va encore plus loin en supprimant entièrement la complexité administrative associée à cette activité.
Si vous connaissez notre mécanisme existant de rotation des tâches de copie des sauvegardes (grand-père – père – fils [GFS]) de la v8, le concept reste le même ici, et il devrait donc être facile à comprendre. Lorsque les sauvegardes complètes sont dirigées vers le pool de supports GFS dans la configuration de la tâche de sauvegarde sur bande, les bandes correspondantes seront conservées selon un modèle de rétention spécifié en semaines, mois, trimestres ou même en années, aussi longtemps que votre stratégie de rétention des données l’exige.
Avec un pool de supports GFS, moins de bandes sont nécessaires pour obtenir une rétention plus longue. Par exemple, le modèle de rotation GFS configuré pour maintenir 4 années de sauvegardes complètes ne demandera que 19 bandes : 4 hebdomadaires, 12 mensuelles et 3 annuelles. Un pool de supports simple est encore disponible pour la rétention de sauvegardes complètes à court terme et les sauvegardes incrémentielles, et vous pouvez donc décider quel pool de supports correspond le mieux à votre scénario de rétention des données.
Et vous pouvez voir grâce à ce seul article de blog qu’il y a plusieurs améliorations importantes des fonctionnalités destinées aux grandes entreprises à venir dans la v9. Et croyez-moi, nous ne faisons que commencer à publier les annonces, car les fonctionnalités de niveau entreprise les plus intéressantes restent encore à dévoiler. J’espère que nos efforts démontrent clairement que nous attachons une grande importance aux besoins uniques de nos clients entreprise, et nous sommes déterminés à vous fournir un produit adapté à 100 % à vos attentes, et qui pourra facilement évoluer pour maintenir un niveau de disponibilité constant pour votre activité en expansion.