La próxima Veeam Availability Suite v9 incluirá, entre muchas características nuevas e increíbles, más mejoras para entornos Enterprise. En estos entornos, suelen surgir dos características principales, que requieren soluciones adecuadas: escalabilidad y administración de múltiples oficinas remotas/sucursales (ROBO).
Una de las grandes capacidades avanzadas de nuestro software es la interacción con el sistema operativo huésped (guest) de las máquinas virtuales protegidas para realizar un respaldo y una restauración adecuados. Al ser una solución sin agentes, nuestros trabajos de respaldo implementan un proceso de tiempo de ejecución temporal en cada máquina virtual para la que se activa el “Procesamiento de imágenes con reconocimiento de aplicaciones”. Este proceso es responsable de la organización de procesamiento de VSS y de ejecutar pasos de backup específicos para las aplicaciones, como el truncamiento de registros (logs) y el indexado de los archivos del sistema operativo guest.
Antes de la v9, todas las interacciones con archivos guest eran realizadas por el servidor de backup. Para cada VM protegida, la consola central implementa el proceso de interacción guest directamente en la VM (ya sea directamente en el sistema operativo guest por medio de la red o utilizando VIX API por medio de una conexión a un host para guests en redes desconectadas). Este proceso siempre ha funcionado a la perfección, pero a medida que crecían los entornos protegidos, en tamaño y complejidad, aparecieron dos límites aparentes.
El primero, la escalabilidad. El procesamiento guest se administra con el servidor de backup, pero, con el tiempo, la cantidad de VM protegidas en un entorno de cliente típico ha crecido de forma tan significativa que los recursos del servidor de backup comenzaron a padecer del efecto “cuello de botella”, lo que limita la cantidad posible de interacciones guest simultáneas antes de que los trabajos comiencen a experimentar tiempos de espera.
El segundo límite está relacionado, en cierta forma, con el primero. Por lo general, los entornos Enterprise también cuentan con varias oficinas remotas, con entornos virtuales implementados de forma local para servir a los usuarios de aquellas sucursales. Dado que en esos escenarios el servidor VBR suele implementarse en las oficinas centrales, todas las interacciones guest deben realizarse por medio del enlace WAN, que suele ser lento.
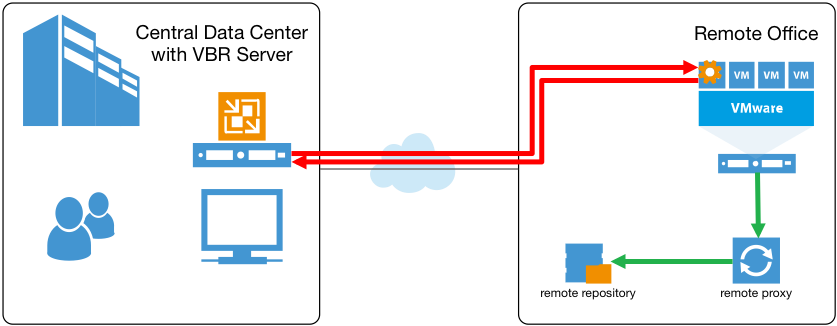
Entonces, incluso si se desarrollara un proxy remoto o un repositorio en la sucursal para mantener el tráfico local de respaldos y restauración, el tráfico de la interacción guest aún necesitaría cruzar WAN, lo que produce problemas de escalabilidad para tales entornos.
Para mejorar el rendimiento, la v9 incluirá un Proxy de interacción guest. Los clientes pueden asignar este rol virtual a cualquier Windows Server administrado (incluidos los proxies y los repositorios de respaldo existentes). El proxy de backup remoto en una sucursal suele ser el candidato ideal, ya que es el más cercano a las máquinas virtuales que protege:
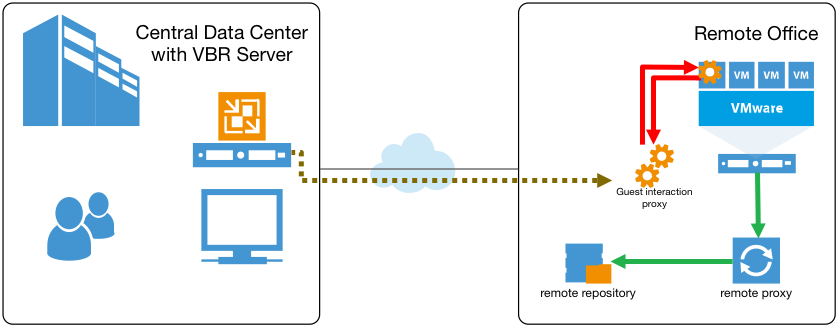
Con el Proxy de interacción guest instalado, el servidor de backup solo enviará comandos de control a través del enlace WAN. El Proxy de interacción guest “local” cargará el proceso de interacción guest a las VM procesadas. Como resultado, se minimizará el tráfico que atraviesa el enlace lento y se reducirá la carga del servidor VBR. Además, como un solo servidor de backup podrá controlar múltiples proxies de interacción guest, la escalabilidad mejorará en gran medida. Por ejemplo, piense en un usuario de Enterprise con 500 sitios remotos. Ahora, este negocio puede designar el proxy de backup de cada sitio para que actúe como el proxy de interacción guest, todo controlado desde el servidor de respaldo central. Y, desde luego, también pueden utilizarse múltiples proxies de interacción guest en un único centro de datos grande para mejorar el rendimiento y la escala de actividades de interacción guest.
Otro beneficio oculto de esta funcionalidad, que quizás no sea evidente a primera vista, es obtener acceso al sistema operativo guest cuando el procesamiento sin conexión de red por medio de VIX no sea posible; por ejemplo, cuando no puede proporcionarse la cuenta de interacción guest requerida de alto privilegio debido a cuestiones de seguridad. Básicamente, ahora puede designar un equipo Windows con NIC tanto en redes de producción como de respaldo y aprovecharlo como un proxy de interacción guest para “enviar” comunicaciones de la red de respaldos a la red de producción.
Pero los respaldos siempre son solo parte de la historia. Una vez que los datos estén almacenados de forma segura en un repositorio, quizás sea necesaria una restauración. Y, si observamos nuevamente este caso desde el escenario de la oficina remota, actualmente, las restauraciones a nivel de archivo deben estar dirigidas por un servidor de respaldos central, con archivos de respaldo montados directamente en este:
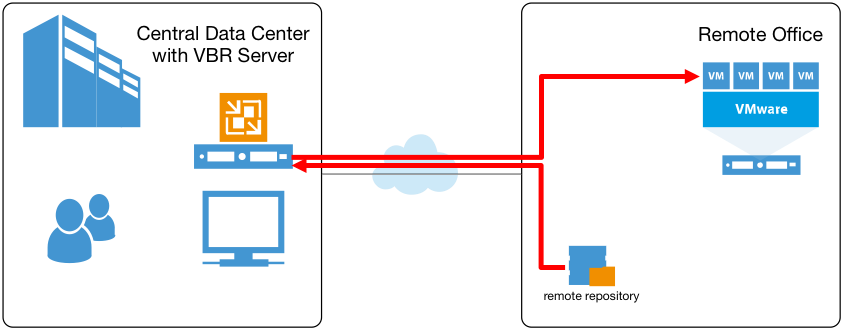
Entonces, incluso si el repositorio de respaldos fuera “local” en relación con el entorno virtual remoto, durante las restauraciones a nivel de archivo local, los datos deberán atravesar el enlace WAN lento dos veces: primero se envían al servidor de respaldos y, luego, regresan a la máquina virtual en el sitio remoto. Una solución alternativa popular es utilizar el asistente de restauración a nivel de archivo (FLR) para múltiples sistemas operativos con la aplicación de ayuda de FLR ejecutada en el sitio remoto; sin embargo, este método tiene sus propias desventajas.
Con la v9, esto ya no es necesario gracias a la nueva configuración Mount Server para cada repositorio de respaldos. Básicamente, ahora cualquier Windows Server administrado con Veeam puede designarse como un punto de montaje de FLR para respaldos de Veeam. Y, desde luego, ¡no hay una mejor opción para una oficina remota que un repositorio existente basado en Windows sea su propio host de montaje!

Actualmente, gracias a este nuevo rol virtual, el servidor de VBR central solo enviará comandos de control por medio del enlace WAN, mientras que el backup remoto se montará con el servidor de montaje “local” designado para restaurar los archivos requeridos directamente en la máquina virtual remota, y todas las trasferencias de datos permanecerán dentro del sitio remoto.
En relación con las operaciones “remotas”, otro agregado muy importante que se incluirá en la v9 es una consola independiente. Sí, nos referimos a la muy esperada consola Veeam Backup & Replication que los administradores de Veeam podrán instalar por separado del servidor de respaldos, como en sus propias estaciones de trabajo, y que permitirá administrar el servidor de respaldos de forma remota por medio de la red. Dígale adiós a las sesiones de RDP o a aquellas con múltiples usuarios luchando entre ellos para conectarse al mismo servidor de respaldos, ya que ahora cada operador podrá tener su propia consola. Es importante destacar que la consola también asume el rol de un servidor de montaje para escenarios de recuperación avanzados en los que deben montarse respaldos locales (como para Veeam Explorer); una capacidad que será muy útil en escenarios ROBO.
Pero, ¡eso no es todo por hoy! Como ya pudo observar en la v8, estamos completamente comprometidos a proporcionar el mejor soporte de cinta del mercado para clientes de cualquier tamaño; la v9 traerá muchas mejoras adicionales en las funcionalidades de cinta que nuestros clientes de Enterprise han estado esperando con ansias. Solo explicaré las más importantes, ¡pero puedo asegurarle que hay muchas mejoras más!
La primera, y, en mi opinión, la más importante, es la capacidad de crear un conjunto de medios que se desprende de una única librería de cintas física y que es capaz de abarcar datos a través de múltiples librerías de cintas. Este “conjunto global de medios” se convertirá en el principal objetivo cuando se trate de trabajos de cintas y mejorará el rendimiento y la experiencia general de administración.

Un trabajo de cinta en el “conjunto global de medios” puede utilizar múltiples librerías de cintas o unidades independientes dependiendo del orden de failover (conmutación por error) de la librería configurada y cambiar a una de las librerías disponibles si ocurre un evento de failover. Por ejemplo, imagine que a una librería se le acaban los medios gratuitos, o que tiene todas las unidades de cinta ocupadas. Gracias a los conjuntos globales de medios, un trabajo de cinta puede cambiar a otra librería que aún tenga medios gratuitos o unidades de cinta disponibles.
¿Qué otras características se incluirán en el rendimiento operativo de cinta? En la v9, ¡estará disponible el procesamiento paralelo entre múltiples unidades de cinta, tan solicitado por los clientes! Lo que antes requería configurar múltiples conjuntos de medios y trabajo de respaldos de cinta, con una complejidad incrementada, ¡ahora está disponible de inmediato!

Esto será una opción simple, pero poderosa, que le permitirá ejecutar simultáneamente trabajos de cinta orientados al mismo conjunto de medios o expandir el archivado de los archivos de respaldo fuente entre múltiples unidades.
A continuación, hablemos acerca de la rotación de medios de cinta. Estoy seguro de que muchos de ustedes estarán felices al escuchar que habrá un nuevo tipo de conjunto de medios disponible en la v9: el conjunto de medios GFS dedicado a respaldos completos. De manera similar, aunque es posible lograr casi el mismo resultado con múltiples conjuntos de medios en la v8, la v9 va más allá al quitar por completo la complejidad asociada a la administración.
Si está familiarizado con nuestro mecanismo de rotación abuelo – padre – hijo (Grandfather – Father – Son: GFS) de trabajo de copia de respaldo en la v8, el concepto sigue siendo el mismo, por lo cual debería ser sencillo de entender. Cuando los respaldos completos se orientan al conjunto de medios GFS en los tipos de configuración de trabajos de respaldo a cinta, las cintas correspondientes se mantienen según un esquema de retención específico, que involucra semanas, meses, trimestres e incluso años, en la medida que su política de retención de datos lo requiera.
Con un conjunto de medios GFS, se necesitan menos cintas para obtener una retención más prolongada. Por ejemplo, el esquema de rotación GFS está configurado para mantener 4 años de respaldos completos en solo 19 cintas: 4 semanales, 12 mensuales y 3 anuales. Todavía están disponibles los conjuntos de medios simples para retención de respaldos completos a corto plazo y respaldos incrementales; por lo tanto, usted es quien decide, en última instancia, qué conjunto de medios se adapta mejor a su escenario de retención de datos deseado.
Como puede ver tan solo desde esta publicación de blog, hay una gran variedad de mejoras significativas de las funcionalidades específicas para Enterprise en la v9. Y créame, recién comenzamos con los anuncios, aún no revelamos la mejor funcionalidad de Enterprise en la v9. Espero que nuestros esfuerzos hayan demostrado claramente que le prestamos atención a las necesidades únicas de nuestros clientes de Enterprise, y que estamos determinados a proporcionarle un producto que esté 100 % preparado para Enterprise y que se pueda escalar fácilmente para mantener la disponibilidad para su negocio en crecimiento.