This article is aimed at giving you a smooth start with Veeam Backup & Replication. It includes some basic advice on the initial setup, and outlines the most common misconfigurations that we, at Veeam Support, find in clients’ infrastructures during our investigations.
Recommendations on backup modes
In most cases, forward incremental or forever forward incremental backup modes are recommended as the fastest ones. Forever forward incremental (no periodic full backup) requires less space and offers decent performance. Forward incremental requires more space, but is also more robust (because a backup chain is further divided in subchains by periodic full backup).
Reverse incremental backup method is our oldest backup method and consequently the slowest. Depending on the type of storage in use, it can be three or more times slower than other modes. With the reverse incremental backup, you get a full backup as the last point in the chain. This allows for faster restores in case the most recent point is used, but the difference is often negligible in comparison to a forward incremental chain (if its length is not unreasonably long, we usually suggest it to be around 30 days).
Insights on the full backup
Synthetic full operation builds a full backup file from the restore points already residing in your repository. However, not every storage type provides a good performance with synthetic operations, so we advise to use active full backup as an alternative.
When you set up a synthetic full backup mode, there is an additional “Transform previous backup chains into rollbacks” option available. Keep in mind though that this option starts a task of transforming incremental backups (.VIB) into rollbacks (.VRB), which is very laborious for your target backup repository. For example, it will help you transform your current chain into the reverse incremental one for archival purposes. However, if you use it as a main backup method, it would produce a very specific backup chain consisting of a full backup file and a mix of forward and reverse incremental restore points.

Guest processing tips
Guest processing is used to create consistent backups of your VMs. And if they run instances of Microsoft Exchange, Active Directory, SharePoint, SQL Server and Oracle applications, you will be able to leverage granular restores using Veeam Explorers.
To enable guest processing, go to Guest Processing of backup job properties. You should enable “Application-aware processing” option and you should provide an administrative account under guest OS credentials.
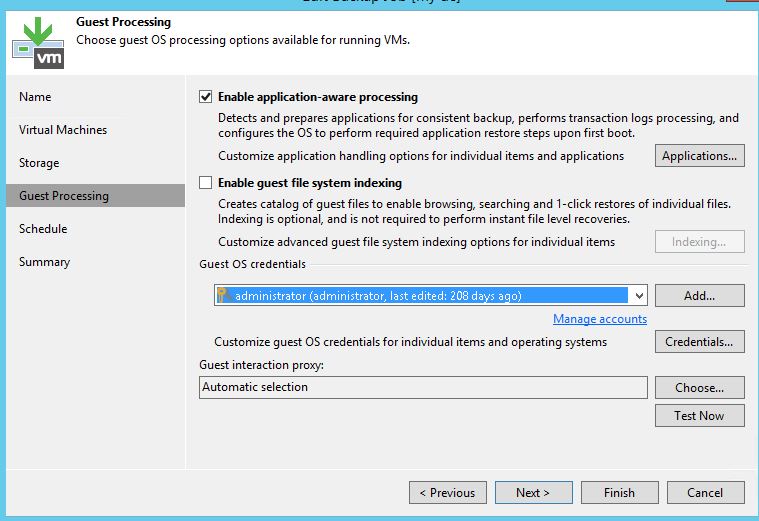
If some of VMs in the job require specific credentials, you can set them by clicking on the “Credentials” button. This brings up the Credentials menu. Click on “Set User…” to specify the credentials that should be used with the VM.

Clicking on the “Applications…” button brings up a menu where you can specify options for supported applications and disable the guest processing for certain VMs, if needed.
VM guest file system indexing
With “VM Guest File System Indexing” enabled, Veeam Backup & Replication creates a catalog of files inside the VM, allowing you to use guest file search and perform 1-click restores through our Veeam Backup Enterprise Manager.
In case you don’t use the Enterprise Manager, then you can cut some (sometimes significant) time off your backup window and save space on the C: drive of a Veeam server by disabling this option. It doesn’t affect your ability to perform file level restores from your Veeam Backup & Replication console.
Secondary backup destination
No storage vendor can guarantee an absolute data integrity. Veeam checks a backup file once it’s written to a disk, but, with millions of operations happening on the datastore, occasional bits may get swapped causing silent corruption. Veeam Backup & Replication provides features like SureBackup and health checks that help detect an early corruption. However, sometimes it may be already too late, so it’s absolutely necessary to follow the 3-2-1 rule and use different sets of media in several locations to guarantee data availability.
To maintain the 3-2-1 rule, right after creating a primary backup job, it’s advised to set up a secondary copy job. This can be a Backup Copy Job to a secondary storage, Backup Copy Job to a cloud repository or a copy to tape.
Instant VM recovery as it should be
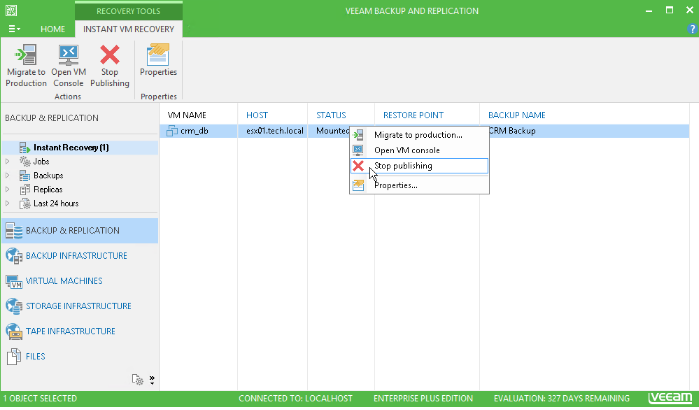
Instant VM Recovery allows you to start a VM in minimal time right from a backup file. However, you need to keep in mind that a recovered VM still sits in your backup repository and consumes its resources. To finalize the restore process, the VM must be migrated back to the production. Too often we at Veeam Support see critical VMs working for weeks in the Instant VM Recovery mode until a datastore fills up and data is lost.
For those of you looking for a deep dive on the topic, I recommend the recent blog post on Instant VM Recovery by Veeam Vanguard Didier Van Hoye.
Mind the CIFS as a main target repository
Veeam is storage agnostic and supports several types of backup repositories. Over the years, it was proven that a Windows or Linux physical server with internal storage gives the best performance in most cases. You can check Veeam Forums for more details — years later, these words still stay true.
Backup repository on a CIFS share still remains a popular choice, yet it generally offers the poorest performance of all options. Many modern NAS devices support iSCSI, so a better choice would be to create an iSCSI disk and present it to a Veeam server/proxy.
Target proxy for replication
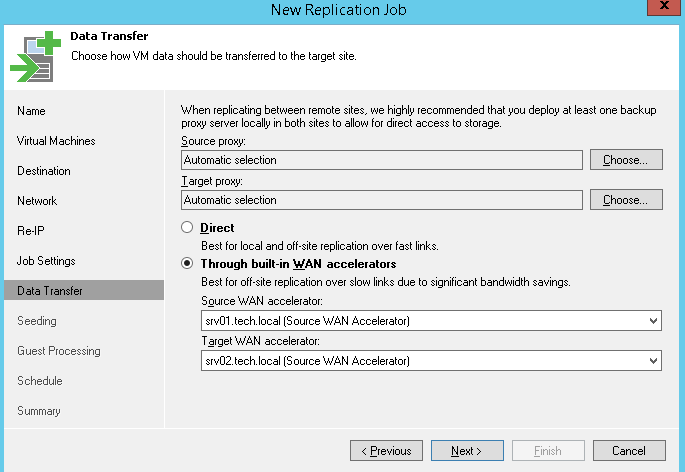
When replicating over the WAN, it is advised to deploy a backup proxy on the target site and configure it as a target proxy in replication job settings. This will create a robust channel between the two sites. We recommend setting a target proxy to NBD/Network mode, as using hot-add for replica can cause stuck and orphaned snapshots.
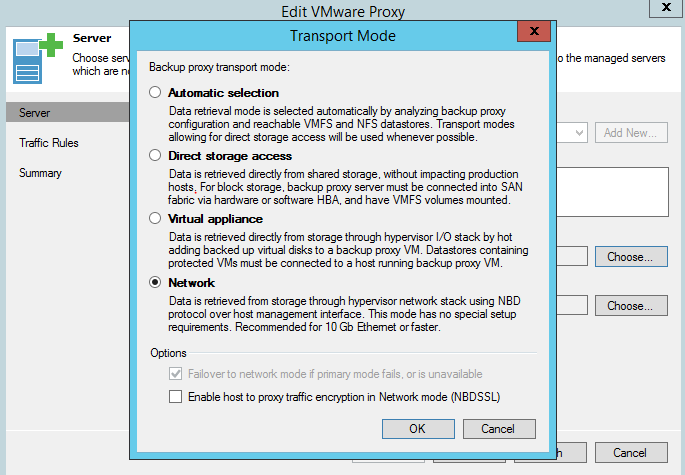
A must-do for a tape server
Tape server is a component responsible for communication with a tape device. It is installed on a physical machine to which a tape device is connected (“pass through” connections via ESXi host to a virtual machine are not supported!).
Veeam Backup & Replication gets the information about the library from the OS, so you should make sure that the latest drivers are installed and the tape device is visible correctly in the device manager.
You can find more info on using tapes with Veeam Backup & Replication in my previous blog post.
Final advice on opening tickets with Veeam support
We encourage you to carefully check the Severity criteria and set an appropriate level when opening your support request. We understand that each issue, no matter the scale, is important and it is our duty to handle it in the quickest way possible, but if you set the Severity to 1 and it doesn’t meet its criteria, you will lose valuable time since your ticket will be inspected and re-directed to an appropriate queue.
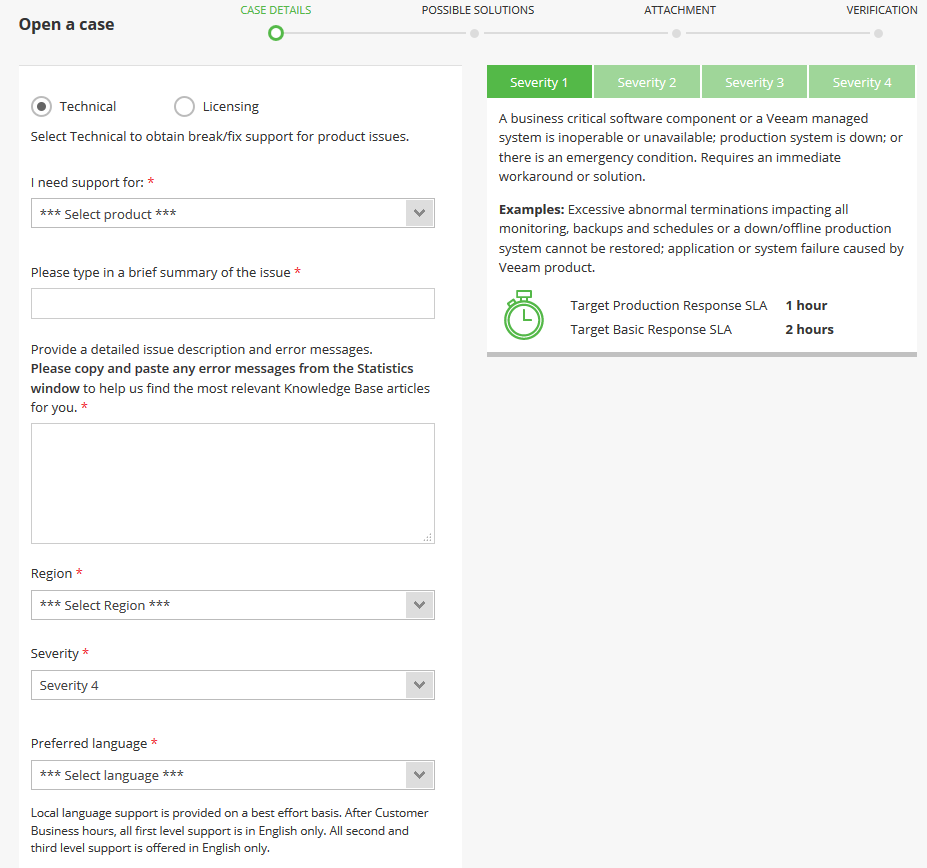
To help our support agents get to the root of the issue straight away, make sure to compile the backbone of every successful case investigation: a log bundle. Follow our guide to retrieve them in a correct way. In some occasions, we might require logs from additional components of your infrastructure, but those would be requested by your support engineer directly.
And that’s it for today’s episode! I hope this would help you optimize your backup environment and evade the most common mistakes during a setup.
See more: