A lot of discussion and thought goes into designing backup solutions for adequate capacity, performance at an affordable cost. Normally the focus is on the backups, but we also need to think about the restores. The faster the restore, the less down time and economical loss. Instant VM Recovery is there to achieve the fastest possible restore time. This works great, but at scale, you need to worry about the performance of those virtual machines you made available so quickly and how the operations involved impact your environment. We’ll discuss some key design considerations to make Instant VM Recovery shine.
If you haven’t heard of Instant VM Recovery, you need to go and read up on it in the User Guide. Veeam describes it as follows:
“With Instant VM Recovery, you can immediately restore a VM into your production environment by running it directly from the compressed and deduplicated backup file. Instant VM Recovery helps improve recovery time objectives, minimize disruption and downtime of production VMs.”
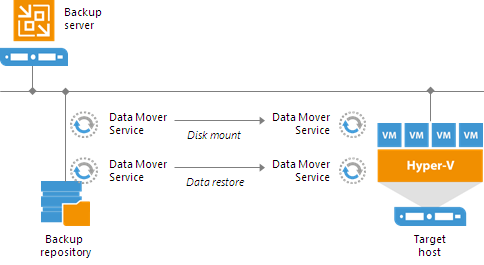
Next to Instant VM Recovery, many design points here will also benefit and optimize “normal” backup and restores. But when time and scalability are the most important factors during restores, Instant VM Recovery is a great feature. The benefit of speed when getting a service up and running is clear. When you do this for only one or a couple of VMs, knowing this option exists might be all you should care about. But when you might have different external and/or internal customers with hundreds or even thousands of VMs, things change a bit. Consider the case when you have a subset of virtual machines that are so important your recovery time objective becomes mission-critical. You can have all the High Availability and redundancy you want, no mission-critical service should exist without a plan to restore it as fast as possible when things go south.
What if you would like or need to restore multiple virtual machines, dozens or more, simultaneously? How do you ensure that the performance of those virtual machines that you got available so fast is adequate and that you can handle the required number of concurrent restores within a certain time frame? On top of that, can you do this without causing too big of a negative impact on the workloads that are still running or that are being restored at the same time?
Optimizing versus overdesigning
I have designed a couple of smaller solutions leveraging Instant VM Recovery for a few mission-critical services. The number of VMs involved ranged from a 6 to 30. I also helped come up with a larger scale design for a broader capability to do so. That scenario was driven by the desire to reduce the time needed to recover from a whole-sale disaster such as either storage corruption (it does happen) or even a ransomware attack. Even when the backups themselves are not affected (different storage than the VMs) or not encrypted so they don’t need to be recovered from an off-site/air-gapped system, restoring might just take too long. That could make paying the more economically feasible option, if that even works (yes, ransomware operations can also have SLA issues). The design aim was to deliver fast, parallel VM restores in combination with known established restore priority for all VMs in order to get up and running as fast as possible. All this at a lesser cost and in less time than paying for the decryption key after one major ransomware attack and decrypting the backups and/or workloads. It is that simple, but perhaps not that easily done. The biggest concern next to speed was to protect disk-based backups form the ransomware. Hardening the repositories and protecting access (Multi-Factor Authentication) is key here. I myself always like to have multiple options to recover data fast like application-consistent SAN Snapshots that are replicated across arrays or air-gapped copies, (i.e. Tape or Virtual Tape Libraries). Some organizations don’t have that capability and for them it’s even more critical to make sure what they have is rock solid.
Optimizing is always about checks and balances, otherwise it becomes geeks indulging in overdesign. To be clear, I’m not stating or claiming you need to be able to restore all your VMs super-fast and without too much performance impact via Instant VM Recovery. However, if you get your 20, 50, 100, … most critical VMs for mission-critical services back online this way, you’ll get your business moving again while you wait for the remainder of the services to come back online. What I have built has sometimes been called over the top, but I have seen too many cases where backups and restores are just a low priority and any solution will do as long as there is one. Normally, that goes well until restore time comes around.
Please note that you always have to look at your backup design and the placement of your Veeam components in multi-site environments when it comes to optimizing for backups and restores. In that respect, Instant VM Recovery is not magic.
Finally, I do not cover the dark moments you will face and need to overcome during a ransomware event. Like your clusters that are not really playing well with encrypted resources. You need to stop the attack or you’ll just be adding new files to encrypt into the environment. Those days are long, dark and far from easy.
Prerequisites to performance
The goal here is to have very fast restores of multiple virtual machines as fast as possible and to have those run without significant performance loss or impact on other workloads. This requires:
- Fast reading from the backup targets
- A fast network fabric for data movement
- A fast restore target (can be the backup source) to ingest all IO involved
That’s where we focus on here. In essence, this is quite simple. You need ample resources (compute, network, storage). Simple is nice, but is it easy to do? Sizing is difficult, but the options and technologies for optimization are not that different for normal versus Instant VM Recovery.
The faster your backup storage target is the better the performance of the instant recovered virtual machines can be as the data is being read from there for both restore and operation of the VM. Your network needs to be able to handle the traffic elegantly. 10Gbps (or better) is the way to go. Finally, the storage, where your virtual machines are recovered to, needs to be performant as well. For one, all the new IO is written there, so you want the storage to be able to handle that while the data is being restored simultaneously from the backup target.
When you’ve taken care of compute, network and storage in terms of performance of individual components (scale up), scale out comes into play. This is where you add multiple backup targets and restore targets for Instant VM Recovery to leverage, to be able to restore more virtual machines simultaneously. Let’s look at this in a bit more detail.
Backup target considerations for Instant VM Recovery
On the backup side we try to have a solution where the most recent backups land on the fast storage, offering great backup throughput. This gets expensive, so we need to offload older backups to a more cost-effective solution. Depending on the storage array, older backups can be tiered down to a less expensive storage or copied to a lower tier backup repository. There are options here with entry level SANs, S2D. Not all solutions provide shared storage nor do they need to. That depends on the requirements for your backup targets Availability. The goal here is to provide a cost-effective and efficient way to store your most recent backups on a performant storage. That could be the first four backups of the day or the daily backups of the past two days, etc. Again, this depends on your needs. This can most certainly involve some SSD or even NVMe layer.
The key point here is that the backups you’ll use in an Instant VM Recovery scenario are most probably the most recent ones from the latest restore points. These reside on a fast storage and as such give the best possible performance during the Instant VM Recovery process. Especially when multiple instant recovery jobs are running and other backup jobs are still active. Data is being read for virtual machine IO as the VM is “instantly” available (disk mount). But data is also being read to recover the VM (data restore). all while other backup jobs might be writing to that target.
Let’s look at some examples. Depending on the scale and budget, you have different options. We’ll look at three of them. Whatever works for you will do, and there are variants on these as well as other options out there.
Example 1
Buy a decent entry-level SMB/SME SAN (that doesn’t have to break the bank any more) with configurable tiering. Have a lower capacity tier 1 storage layer for the backups to land on and set a storage progression policy that moves data older down to a tier 2 higher capacity storage layer. You can build both highly available or non-highly available backup repositories with this. As long as the IOPS and latency can follow, you can add repositories to the SAN. If not, you can have more of them and scale it out. As a rule, try to avoid having the same storage array type for your workloads as for your backups. Firmware bugs that can potentially lead to data corruption do exist and you want to minimize your risk.
Example 2
Deploy Storage Spaces Direct to benefit from High Availability, multiple target servers with ReFS Multi-Resilient Volumes (MVR), providing protection and mirror-accelerated parity that you can size tweak so it can hold “hot” (recently written) data for a while in an SSD mirror before moving “cold” (data that wasn’t accessed when the threshold for moving the data is exceeded) data to the less expensive capacity tier. This has scale up and scale out capabilities.

Example 3
Build a tier 2 backup solution, perhaps only for backups of those VMs that require the fastest possible backup and restores. This could involve a couple of 2TB SSD/NVMe drives with short retention backup jobs and have those backups copied to cheaper, long-term archival backup targets. Those can be on the same repository host(s) or on different ones. You can leverage Veeam Backup Copy jobs to create a tiered backup repository within the same backup repository or between different repositories.

A tiered backup repository example within the same repository for the fas,t most recent backups (less storage capacity) and the older backups (more storage capacity).

A tiered backup repository example with different repositories for the fast, most recent backups (less storage capacity) and the older backups (more storage capacity).
Normally, these solutions are not highly available, but you can add some protection against storage failure in the usual ways.
Note: You will be hammering that “tier 1” in any solution, so make sure you use write intensive models. If you have an AFA with 60 SDD for virtualization workloads, you can get away with MLC as the IO is distributed over all the disks, but in the case of the backup target here, you are hammering a small set of disks continuously. So, design accordingly.
Next, we’ll discuss the network and restore target considerations.