I recently had a situation where I was discussing a scenario with Veeam Backup & Replication deployed completely in the public cloud. In fact, many organizations have the Veeam Backup & Replication server in the cloud and are managing either AWS EC2 or Azure VM backups with Veeam Agent for Microsoft Windows and Veeam Agent for Linux.
In this situation, there was a discussion about some other services in the cloud. In particular, AWS EMR (Elastic MapReduce). There was a discussion about managing the hive scripts that are part of the EMR cluster. I offered a simple solution:
Veeam File Copy Job
Since the Veeam Backup & Replication server is in the public cloud, the EMR cluster can be inventoried. This means it is visible in the Veeam infrastructure. Generically speaking, the Linux requirements for a repository or other Linux functions are documented here. But mainly, Perl and SSH are what is needed to add the EMR cluster into Veeam Backup & Replication. This is shown in the figure below:
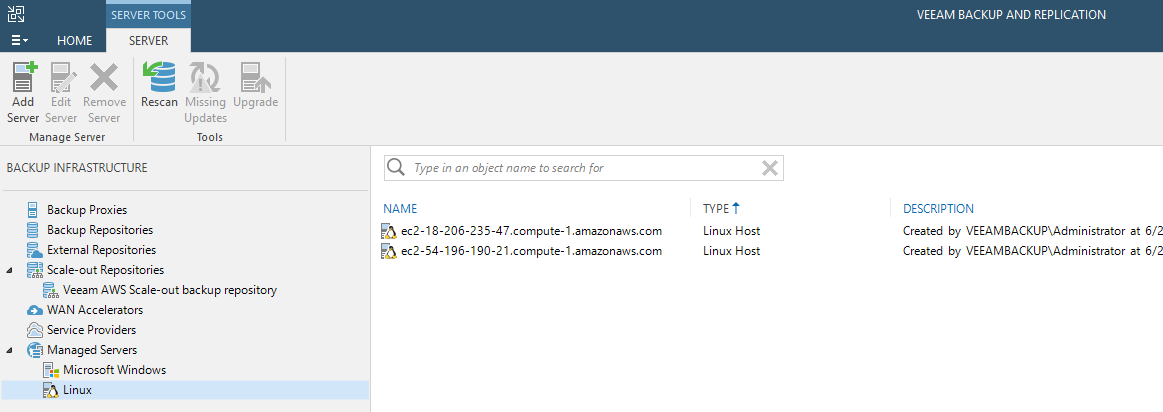
The second entry, ec2-54-196-190-21.compute-1.amazonaws.com, is EMR cluster’s master public DNS entry. From there, it is visible for some basic interaction with Veeam. This reminds me of a challenge I had nearly 10 years ago. I had a physical server with millions of files that I needed to move, the Veeam FastSCP engine saved the day.
I had an odd re-remembering of this situation with the EMR cluster. When you have some hive scripts that are inventoried in EMR, it is possible that Veeam can copy those off to another system so you have a copy of them. It’s important to note that this is not a backup — but a file copy job. Nonetheless, it can be helpful if you have a need to have a copy of your EMR scripts on another system. In the screenshot above, I could copy them to the ec2-18-206-235-47.compute-1.amazonaws.com host as that is a Linux EC2 instance, and I have Veeam Agent for Linux on that system. So, I could have a “proper” backup as well.
One other nice feature here is I can use the Veeam text editor (what used to be the FastSCP Editor). Simply right-click on your hive script and select Edit, this may be easier than dusting off your vi skills:
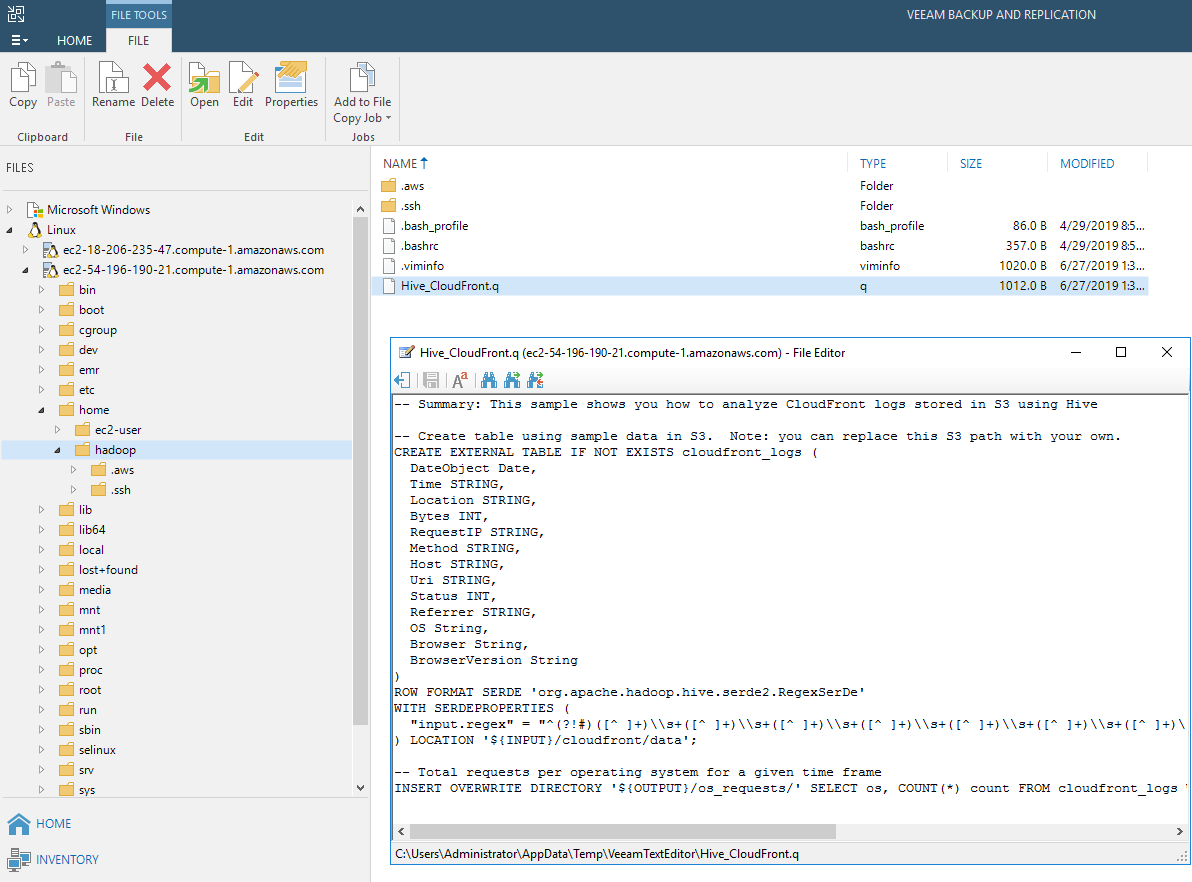
Then from there, I can build the File Copy Job. The file copy job is a simple copy with an optional schedule. You select a source and a target, and it will do just as it sounds. It’s handy in that you can coordinate its schedule with other jobs you may already have in the public cloud. In fact, that’s exactly what I have done in the example below. The file copy job is placing the hive scripts and some other folders I care about from my EMR cluster on a system I’m backing up with Veeam Agent for Linux. That is scheduled to run right after the Linux Agent job. This is a view of the file copy job:

Have you ever used the file copy job? It may be handy for services such as EMR clusters that you need to copy files to or from. You can use the file copy job in the free Veeam Community Edition, download it now and try for yourself.