You may think that VM sprawl has never been a problem for your infrastructure, but what if it IS a problem and you just aren’t aware of it?
What is VM sprawl?
VM sprawl is a symptom of any rapidly growing virtual infrastructure. When any given department in the company opts to run their specific applications on dedicated servers, they can do this, thanks to virtualization. VMs are often set up for temporary usage, like testing or development labs, and after some peak usage owners may forget about them. The more virtualized applications and workloads you have, the more likely that “virtual junk” will appear in your infrastructure and cause VM sprawl. You could say that this is the modern version of the “Server under the desk” phenomena of years past.
It costs real money
The chaotic increase of unmanaged VMs drives extra resource consumption in your environment. Even inactive (idle) VMs still utilize host storage and CPU, wasting the resources you could otherwise allocate to more heavily used applications. Eventually, VM sprawl will exhaust your environment and force you spend some serious money on extra hardware.
How does Veeam Availability Suite keep an eye on VM sprawl?
Veeam Availability Suite delivers more than 80 reports on the VMware and Hyper-V backup and virtual infrastructures with its Veeam ONE component. Let’s see, which reports help you detect key VM sprawl threats and provide you analysis and recommendations on right-sizing and efficient allocation of resources.
Running out of capacity, or where is my free space?
To begin with, let’s note that Veeam Availability Suite features advanced capacity planning which helps to forecast, plan and oversee virtual infrastructure resources (CPU, memory and storage). Next time you look at the Capacity Planning dashboard, a lack of available space (or maybe memory, or both as it is shown on images below) may be an eye-opener for you.

Should you panic immediately purchase additional storage? Keep calm, and use these 5 hints for virtualization sprawl control:
Hint #1. Identify “Zombies”
Actually, they are not really zombies and they don’t eat brains. Instead, they eat up storage space and other resources. The term “zombie” is used for low-activity, idle VMs that are running, yet effectively doing nothing, which sets them apart from high-use production workloads.
Run the Idle VMs report to get a list of idle VMs and decide whether to shut them down, reconfigure their roles or decrease their hardware provisioning. To build this report specify the thresholds for CPU, memory, disk, network usage and the amount of time spent by a VM in the idle state.
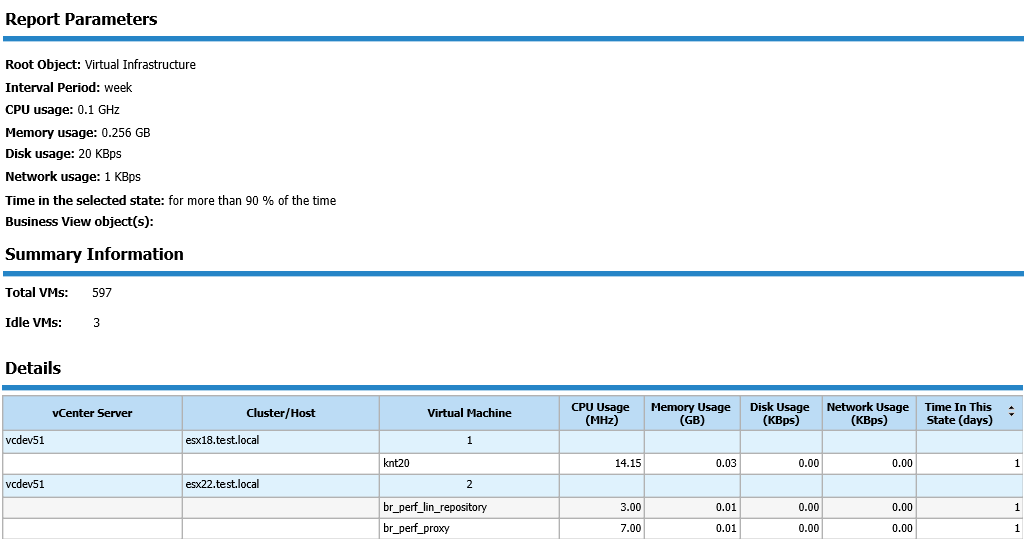
The Idle Templates report shows unneeded objects, which you can either migrate to more capacious storage or simply delete. The key metrics here is the last access to the VM template.

The Inefficient Datastore Usage report catches low-activity zombies and gives you a clear picture of inactive VMs’ locations, the dates they were last accessed and the amount of space allocated to them.

Hint #2. Eliminate excess backups
When your backup repository runs out of space (Capacity Planning for Backup Repository reports will notify you on the matter), check if there are any surplus backups using the VMs Backed Up by Multiple Jobs report. There may be some VMs included into several discrete backup jobs and, thus, sprawling within your repository. Veeam Availability Suite detects the overlapping VMs and shows their target backup locations and referred backup jobs.

Hint #3. Clean up garbage
Garbage files are the side effect of multiple everyday changes in your virtual infrastructure. VM configuration data and temporary files may still remain on the datastore and consume space after their parent objects are deleted.
The Garbage Files report reveals objects, which are no longer being used and points you to these junk files’ locations.

Hint #4: Categorize your VMs
Veeam Availability Suite supports the business categorization of objects in your virtual infrastructure, which can also help you win the virtualization sprawl “war.” Each VM can be assigned to one or several groups by a variety of custom parameters such as department, purpose, specific project and so on. Select a group and you’ll get an at-a-glance view of all of the included machines.
For example, let’s say you’re running a temporary project (let’s say R&D) with a number of VMs. After completing the project, you can open a group of assigned VMs and remove the unneeded ones to free up storage space.

Hint #5. Detect orphaned and old snapshots
As far as we are discussing the problem of wasted resources, specifically on the redundant VMs, VM snapshots are not the case. At the same time, an excessive amount of snapshots influences your infrastructure in the same way, and I recommend you include them in the sprawl control process.
If a snapshot falls out of the relevant snapshot-chain, it is an orphaned snapshot. This may occur after errors such as host failures, inaccurately performed backups and unsuccessful-snapshot consolidation. The sprawl of forgotten snapshots may consume significant storage. VMware recommends keeping up to three snapshots in a chain for a single VM, each for a maximum of 3 days.
The Custom Infrastructure report is based on the Virtual Disk and VM parameters (selected as the object types) and built with custom columns (Name, VMDK file, Virtual Disk: Label, Snapshot: File name, Snapshot: File size) and custom filter (VMDK file – Contains – 0000) will show you a list of all orphaned VMware snapshots in your infrastructure.
You may want to use a step-by-step guide on building this particular type of Custom Infrastructure report, which can be found here in the Veeam Support Knowledge Base.
Another means of snapshot sprawl control is the Active Snapshots report built on snapshots’ age and size metrics. With this analysis, you’ll quickly see which VM snapshots in your virtual environment are the oldest (so most likely you won’t ever need to roll-back a target VM to that state) and the largest.

Set up once and run regularly
To make your life easier, and keep all the reports we discussed above close at hand, you can create a new folder in the Workspace (let’s name it VM Sprawl Control) and save each of the seven suggested reports there. During the first run of each report, you need to specify the required parameters and desired thresholds. When everything is set up, schedule automatic reports delivery for the entire folder and you will always be notified of potential risks in advance.

If you found this post helpful and want to learn more, you can download a free white paper “How to avoid VM sprawl and improve resource utilization in VMware and Veeam backup infrastructures.”