Welcome back for part two of my Cloud Object Storage Deep Dive! If you missed it, in part one we looked at the characteristics that make up the cloud object storage offerings of the main three cloud providers (Microsoft Azure, Amazon Web Services/AWS, Google Cloud Platform/GCP).
Whilst this content will align to public cloud object storage that Veeam currently supports (AWS, Azure, GCP and IBM Cloud), keep in mind that Veeam has currently 26 Veeam Ready – Object storage platforms via their partners. This often is an on-premises deployment, much of the logic applies there too, so don’t overlook the on-premises object storage options.
Now that we understand what to look for from our cloud providers and the features they have available, we’ll look at what information we need to gather to build our own cost and performance estimates to implement object storage ourselves.
What are our important metrics?
Backup size
Primarily, you’ll be backing up data to the cloud and keeping a static copy for your required retention policy, so it’s important to understand both your full backup requirements and the size of your incremental backups as well. This information can be gathered efficiently by navigating to the Veeam Backup & Replication console, then selecting Home, and choosing the backups section, then right-click the backup job you’d like to copy/move to the cloud and choose properties. You’ll see a screen similar to the image below:

The key information provided is the original “Data Size” which is the source virtual machine’s size, the backup size, the deduplication ratio achieved, and the compression ratio achieved. When there are multiple VMs and multiple restore points, it’s possible to click through each job run for each VM to gather these metrics.
Block size
Now that we know the size of our backups, full and incremental, we’re done right? Wrong! Whilst this is a key piece of data, we also need to know the structure of the data. The data block size. Within a Veeam Backup & Replication job, under the “Storage > Advanced > Storage” section, you can define a data block size from the “Storage Optimization” section.

This block size relates to the size of the blocks that Veeam is reading at a time from your VM. Full details of these blocks are outside of the scope of this article, but consider these main points:
- The block size relates to the size of the block that Veeam reads, the size of the block saved depends on the compression ratio. For example, a 50% compression ratio on a 1MB read block is a 512KB block saved.
- The smaller the block size, the better the storage efficiency, meaning smaller incremental backups, but it also means a larger metadata table, which negatively impacts backup performance as larger VMs are targeted with the smaller block sizes. This paves the way for efficient data transfers in and out of object storage however.
The options available and the relative block sizes are listed below:
|
Type: |
Block Size: |
|---|---|
|
Local Target (Large Blocks) |
4096KB |
|
Local Target |
1024KB |
|
LAN Target |
512KB |
|
WAN Target |
256KB |
These block sizes are important, and choosing one comes with a trade-off, each block is one object and results in an API call, so by utilising smaller blocks such as “WAN Target,” you’ll be able to reduce your data footprint to a smaller size, but increased API cost may impact the economic model. More information can be found here. Therefore, each block size will have it’s own characteristics with data put in object storage.
Data tiers
Veeam supports using the cloud as an archive tier and gives you the option to store GFS backups onto an archive tier (Currently for Azure and AWS). As discussed in part one though, archive tiers tend to have minimum retention requirements from the cloud providers and have financial penalties for deleting data retained for a shorter lifecycle. Veeam has safeguards you can put in place to prevent this. When configuring your archive tier, you define at what age backups should be migrated to the archive tier, with the option to also process backups that, based on your retention policy for GFS backups, will meet the minimums specified by your cloud provider.
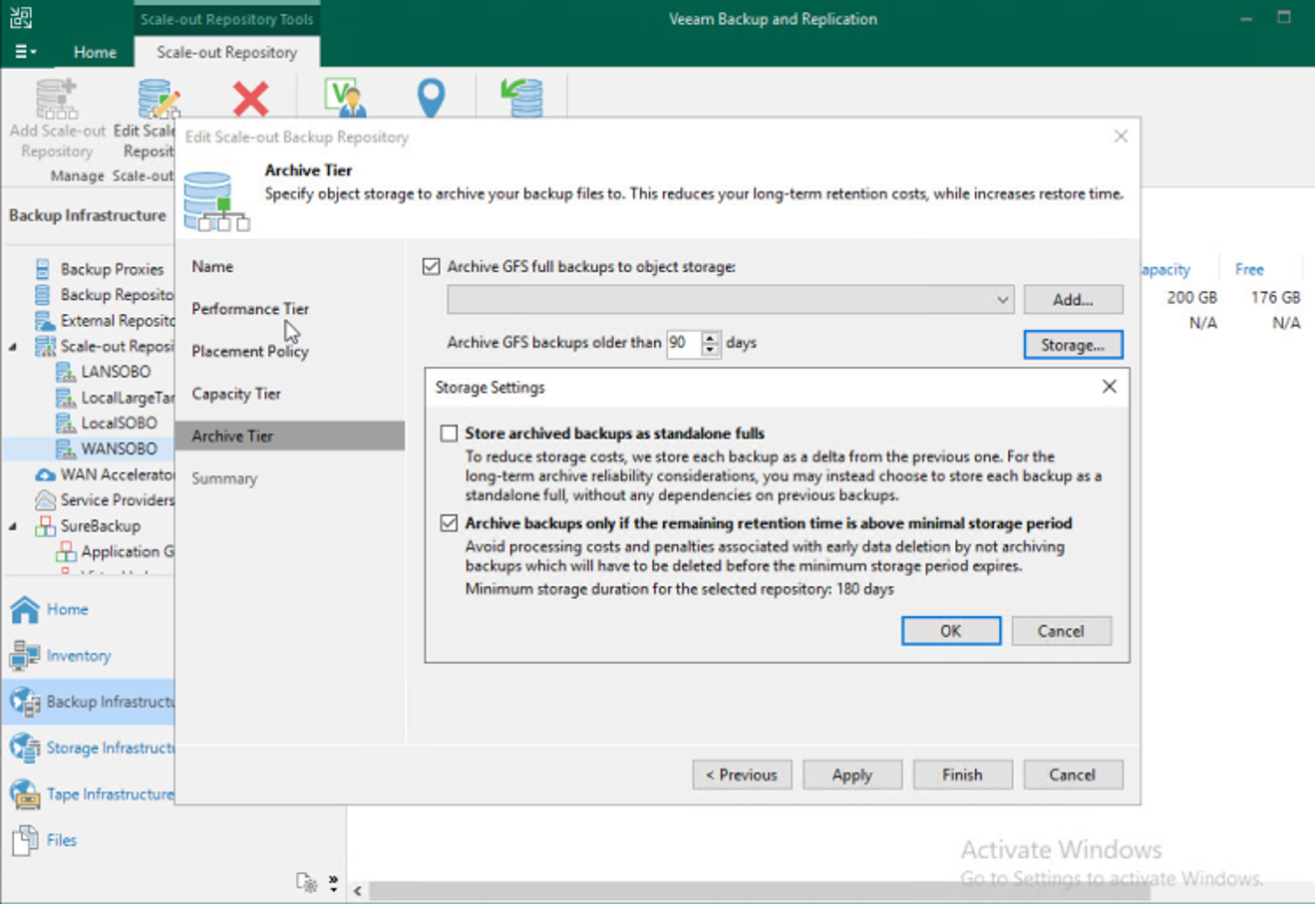
The ability to offload backups to the archive tier regardless of compliance with the cloud provider’s minimum retention policy was a strongly requested community feature as often offloading data to the archive tier and then deleting the data shorter than the required minimum and incurring the penalty was still cheaper than using the capacity tier for the required length of time, but be sure to check before you disable this setting. More information on the capacity tier is here. More information on the archive tier is here.
How do we calculate our costs based on these metrics?
To create our realistic estimations, lets put this information to work. The best way to review this is to look at different object storage scenarios and the metrics involved in these operations.
Scenario one: Backing up data to object storage
When we back up data, we incur the following costs:
- Storage – Potentially the most obvious one, you’re increasing your utilised storage, even if only temporarily before a retention policy is applied, so this will be billed accordingly. This is billed for the duration the data exists within the object storage.
- Write Operations – (Also known as a PUT) Most object storage providers will charge whenever you perform an operation against the object storage, in this case you’ll incur charges to write the data. Each block written is an API call (refer back to the “Block Size” subsection for further information), so depending on your block size you can perform the following calculation to get an estimate of the number of API calls required to save a backup to object storage. The formula is: (Backup size in MB) * (1024 / Block Size). Storage Tier – The tier you choose to initially store your data within will affect the price of each GB of storage or each API call.
Scenario two: Restoring data from object storage
By recovering data, we incur the following costs:
- Read Operations – (Also known as a GET) Most object storage providers will charge for read API calls against their storage in addition to writes, so in this scenario, we’ll be charged for fetching the data from object storage.
- Bandwidth – Whilst most object storage providers provide bandwidth ingress for free over the public Internet, far fewer will provide egress bandwidth for free.
- High-Priority Access – Archive tier data tends to not be readily accessible and requires retrieval. Some object storage providers will offer a high-priority data retrieval option at a much more significant cost.
Veeam attempts to reduce the cost of data retrieval from object storage by fetching any blocks that are stored locally, from local storage, even if the required backup isn’t stored locally in its entirety.
Scenario three: Retention policy processing
Eventually, your backups will be aged to the point that they’re no longer required, when this happens, it’s possible to incur costs.
- Early Deletion Fees – Depending on the storage tier your backups are currently homed to, backups being deleted when they haven’t existed for the minimum data retention set by the object storage provider will lead to deletion fees.
- List API Calls – Are used to help process delete operations. Pricing varies per vendor.
- Deletion API Calls – Some object storage providers will charge for API calls to delete objects. This can also be charged at either a per-object or per-block level. This is uncommon but does exist.
- (Demoting Storage Tier) Write API Calls (Also known as a GET) – If a backup is being demoted to a slower tier, this usually incurs a write API call, causing additional expense as part of the operation.
- (Demoting to Archive Tier) Proxy Appliances – To improve the efficiency and reduce the costs of the data transfer process, Veeam deploys temporary proxy appliances within the cloud provider of choice. These appliances will consume compute resources temporarily to configure an optimized object size for the object storage target. Veeam automatically tidies these up after the processing is complete. As this can be a combination of several operations this will incur Read, Write, List and Delete API calls.
Conclusion
We’ve now seen how settings within Veeam can impact the efficiency of using object storage and how different operations can incur costs. In part three we’ll perform some benchmarks to provide real figures to highlight the impact these changes can make to the performance and cost of using object storage.
Related Content: