Welcome to the final part of our three-part series on Veeam and object storage. In part one we looked at the similarities and differences between the big three “hyperscale” cloud providers, then in part two we looked at how Veeam can be configured to optimise your object storage utilisation and efficiency. Now in part three we’ll look at some benchmarks to provide real results to help shape your object storage designs. Enabling you to accelerate your adoption of object storage in an effective manner.
Basics
To ensure this test was as fair as possible, I created a single VM, installed Windows Server 2019 and shut it down. I then created a backup job with some common attributes detailed below and cloned the backup job three times. Within each of these clones I only changed the block size and the repository (all separate folders within an NTFS 4k partition), ensuring all other settings were identical.
The environmental settings configured were:
- Local repositories were all configured to align backup file data blocks.
- Each repository was configured as a Scale-out Backup Repository (SOBR) with a separate object storage, for my testing I created 4x storage accounts, each one within a different resource group within Microsoft Azure. The SOBR was configured for copy mode in each instance.
- All cloud repositories were hot tier, LRS storage within the same region (UK – South).
- Guest Processing was disabled, with the VM shut down to ensure the blocks were identical per backup.
- Compression Level was set to optimal
- Inline Data Deduplication, Exclude Swap File Blocks and Exclude deleted file blocks were all left to defaults (enabled).
- Jobs were configured as forward incremental
- Job schedule was disabled, ensuring the VM data was identical for each job run.
Full and incremental run
With the jobs configured as above, I ran the initial full backups and documented the API calls generated from Microsoft Azure and the file space consumed on the NTFS partition by the VBK files only. I then proceeded to boot up the VM, download the latest Veeam ISO to its storage and then shut the VM down once more. I then ran the incremental runs from each backup job. Once the job runs were completed, I collated the results.
Results
First, let’s take a look at the API requests:
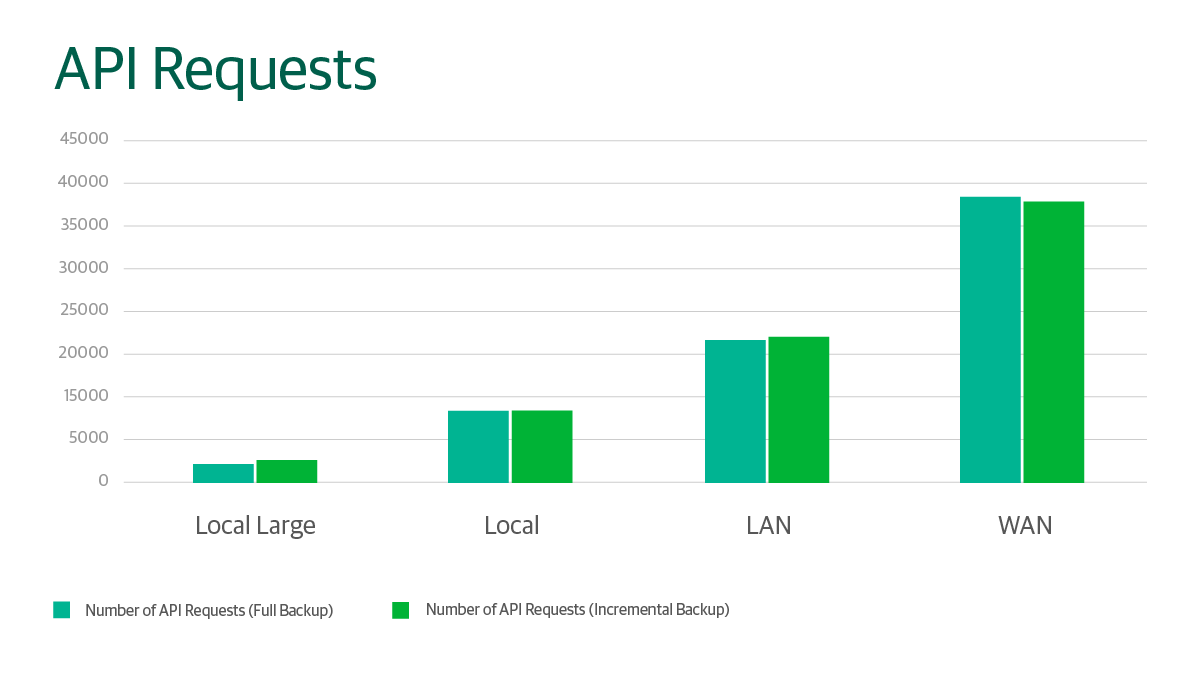
Graph showing the disk space consumed for backup and incremental job runs relative to the storage optimisation selected. See table below for breakdown.
|
Block Type |
Full Backup Size (MB) |
Incremental Backup Size (MB) |
Full Backup Size – Relative to Local |
Incremental Backup Size – Relative to Local |
|---|---|---|---|---|
|
Local Large |
5842 |
9445 |
99.73% |
103.43% |
|
Local |
5858 |
9132 |
100.00% |
100.00% |
|
LAN |
5862 |
9055 |
100.06% |
99.16% |
|
WAN |
5896 |
9081 |
100.65% |
99.44% |
When running our full backup, the smaller block sizes actually gave us a slight storage consumption penalty in addition to the massive increase in API calls. If you’re wondering why we still have LAN/WAN as target options with these results, it’s because we’ll see the benefit within the incremental backups. At this point we see that Local Large goes from being our overall favourite to suffering its first loss, with an increase in storage of over 3%, whereas we start to see LAN and WAN being more reserved with the storage they require for the incremental backups. Remember that for this example, the changes for incremental backup were generated by copying files to the VM. The increase in storage used based on block size will vary depending on the workload type.
Note that it is also possible to choose a larger block size of 8 MB by enabling a registry key in Veeam Backup & Replication v11a.
Cost
Whilst it’s been intriguing to review all these numbers, what really matters is what this will cost you. So let’s take a look at the end result, as prices vary month to month, here’s a snapshot of what the costs were at the time:
Storage Per GB: £0.015 per month
|
Block Type |
Total Storage Required (MB) |
Storage Cost Per Month |
Total API Calls Required |
API Costs |
Total Cost: |
|---|---|---|---|---|---|
|
Local Large |
15287 |
£0.23 |
5270 |
£0.02 |
£0.25 |
|
Local |
14990 |
£0.21 |
19590 |
£0.09 |
£0.30 |
|
LAN |
14917 |
£0.21 |
38660 |
£0.17 |
£0.38 |
|
WAN |
14977 |
£0.21 |
76140 |
£0.33 |
£0.54 |
Closing comments
Whilst the test sizes here are small, they scale. Collating this data together gives us this table:
|
Block Type |
API Calls Per MB |
|---|---|
|
Local Large |
0.34 |
|
Local |
1.31 |
|
LAN |
2.59 |
|
WAN |
5.08 |
Veeam’s average expectation varies from this and is used in lieu of specific workload testing, if in doubt refer to this table:
|
Block Type |
API Calls Per MB (Average) |
|---|---|
|
Local Large |
0.25 |
|
Local |
1 |
|
LAN |
2 |
|
WAN |
4 |
Backup Size * Block Size (0.25 for Local Large | 1 for Local | 2 for LAN | 4 for WAN)Conclusion
We now have reached the end of part three, where we see these metrics in practice. To summarise, in part one we compared the “Big Three” main hyperscale cloud providers and reviewed what made them similar and different, in part two we reviewed the settings available within Veeam to optimise our object storage utilisation and the different scenarios we should plan for when working with object storage. Finally, in part three we created a benchmark against which we now have realistic expectations as to the costs associated with the clouds.
As with all backup data sets and cloud use cases, your mileage may vary. This is a point of view for one deployment as shown but gives you a perspective on how cloud storage can be used for Veeam backups.
Thank you for reading and please let us know if you have any questions or comments regarding this series.