Read the full series:
|
Ch.1 — Backup Server placement and configuration |
I’m enjoying this series of blogs! This is a great way to share information about the best practices for the VMware backup experience. This post will now vary slightly from the other two and talk about the backup repository. This was another breakout session from Anton Gostev at VeeamON 2015 (those who attended were lucky to get the live experience) and will surely be a great one to catch in 2017 in New Orleans. This will be written in mind of Veeam Backup & Replication v9, but can be a starting point to making good changes in your environment.

Backup Repository General Considerations
There isn’t a single choice that is the best for all situations such as change rates, sizes, expectations, budgets, etc. Don’t underestimate the importance of a performant backup repository, it’s one of the most commonly reported sources of slow backup performance. This will also be an issue on the restore job, so RTOs could be impacted. I’ve written a long time ago on “The Ultimate VM Backup Storage Architecture” with Veeam, and many of those principles apply. Here’s a look at the latest view of the Ultimate VM Backup Storage Architecture:
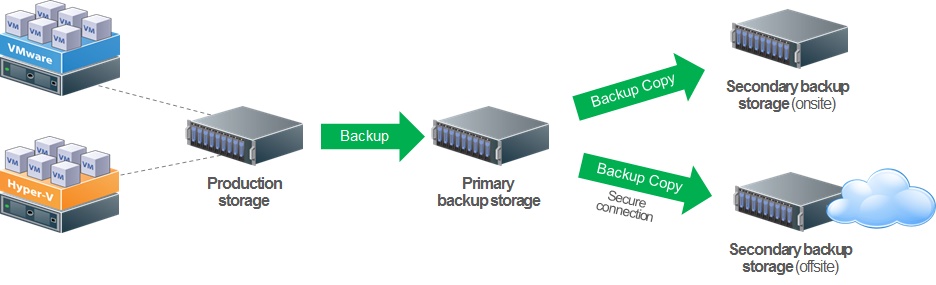
There are few key characteristics of this architecture that are important, regardless of the pieces and parts in your environment and source data profiles:
- There is fast, reliable primary-class storage for the fastest backups and restores (and it has low latency to the source data)
- You can control the number of restore points on the primary backup storage resource (say 2 or 3 restore points and no synthetic full backups on disk)
- Must have at least one copy of the backups elsewhere, such as on a deduplication appliance
- Then selectively put the data on tape, in a DR (disaster recovery) site or in a cloud
Key things to avoid
Based on user experiences and practical implementations, here are a few things to avoid when it comes to backup repositories:
- Avoid low-end NAS and appliances: If you have one unavoidably, use iSCSI instead of NAS protocols.
- Generally avoid CIFS and SMB: If it is a share backed by an actual Windows Server, add that instead.
- Avoid placing backups on VMDKs on VMFS volumes: There are many steps on the data path which can introduce corruption and it requires vSphere to do a recovery (inception).
- Watch the scalability of Windows Server 2012 deduplication: The official language is that “Files approaching or larger than 1 TB in size” are not supported. Going into the future Windows Server 2016 has significant improvements, so this is a short-term recommendation now.
- Generally making deduplication appliances the primary backup repository.
Raw disk and backup job considerations
We often get the question on what RAID levels should be used for backup repositories when dedicated storage is used to hold Veeam backups. Generally speaking, the following attributes apply to standard RAID levels:
| RAID Level | Characteristics |
| RAID 10 | Use whenever you can (2x write penalty, but capacity suffers) |
| RAID 5 | Use as the next economical choice (4x write penalty, but greater risks) |
| RAID 6 | This has the most severe performance overhead (6x write penalty) |
There are also a few points on stripe sizing if you can configure this on your RAID volume. Typical I/O for Veeam is 256KB to 512KB, Windows Server 2012 defaults to 64KB, some arrays to 32KB. That’s a lot of wasted I/Os! A stripe of 128KB is recommended. Additionally, use as many drives as possible to avoid expansion at a later time (which divides performance across RAID arrays).
In regards to the file system, NFTS is commonly used. The larger block size doesn’t affect performance but it can help avoid excessive fragmentation; therefore a 64KB block size is recommended. Use the format with /L option for larger file records. There was a 16TB max file size limit before Windows Server 2012 (which increases it to 256 TB). This information applies to v9 and earlier; but watch for updates on Veeam Availability Suite 9.5.
In regards to the job settings, there is always a trade-off between performance and disk space. This can also be amplified by the different types of data in use (high change rate environments for example). The reversed incremental backup job mode carries a 3x I/O cost per block moved; making the forever forward incremental backup mode more attractive.
Keep in mind the concurrent job setting to set a reasonable amount of inbound data to the backup repository as well as the ingest rate setting for backups from SAN-based backups (which can move fast).
Deduplication Appliances!
Backups are a good profile for deduplication, especially when many full backups are on disk. There are significant benefits on lowest cost per TB with global deduplication (but many devices implement it differently). The real pain is the random access performance (of a restore) as deduplication appliances are built for sequential I/O generally speaking. Additionally, getting data into (and out of) a deduplication system generally isn’t as fast as its general purpose counterparts. Lastly, there can be significant upfront cost.
That being said, there still are significant gains to be had. Veeam has three integrated targets for deduplication and they are built right into the user interface:

This makes a few specific recommendations for leveraging Veeam with deduplication appliances:
- Leverage the integrations we have with deduplication appliances!
- Use backup modes without full backup transformations
- Use Active Full backups vs. Synthetic Full backups if possible (the random reads…)
- Consider VTL modes
- Note that parallel processing may impact your deduplication ratios slightly; limit to 1 task instead of disabling parallel processing
- In backup jobs, use the 16TB+ option for 4MB blocks (new in v9):

One guiding principle here is to give yourself lab time and a predictable I/O pattern to run these options and recommendations through to see what kind of difference they make in your environment. This is especially relevant if you don’t have one of the vendor specific integrations with Veeam. This is a great opportunity to test the Backup Copy Job retention performance when synthetic full backups are made. Since v9, the ability to do an Active Full option in the Backup Copy Job can help in performance here.
One important thing to make sure is that the dedupe-friendly compression setting is used in backup jobs. This will help performance of the backup job with little trade-off on the deduplicated target. Many people ask if Veeam’s deduplication (in the backup job) should be turned off; and it generally is fine to leave on.
The most significant recommendation with deduplication is to not overdo it however. Don’t get the deduplication ratio super-high, in the end they just take up more CPU and processing time for marginal space savings.
The Scale-out Backup Repository
v9 introduced the Scale-out Backup Repository for Veeam Backup & Replication. It’s a great way to simplify the backup storage and job management, reduce storage hardware spend and improve backup storage performance and reliability. Check out the whitepaper from Luca Dell’Oca on the Scale-out Backup Repository, which was written after v9 went available and some practical feedback was implemented into the recommendations in this whitepaper.
Stay tuned for more posts in this series! Until then, here are some resources you can use to supplement this blog post: