I’ll wrap up my “Replication 101 series” with an overview of recovery options from VMware VM replicas available in Veeam Backup & Replication v8 (a part of Veeam Availability Suite v8). I’m going to walk you through failover basics, including planned failover and failover plans, which can help you automate disaster recovery (DR). Keep reading to learn how to safeguard your critical applications from failures and downtime.
Failing over to a VM replica
Replica failover is switching from a damaged or failed production VM to its replica on a remote location. Replicated VMs are stored in a fully functional, ready-to-use-state, so failing over requires just a few seconds to power on the VM. You don’t need any additional configurations or apply extra settings, because replicas have exactly the same configuration as their source VMs. To initiate a failover, right-click the required VM replica and choose “Failover Now” to start the failover wizard.

You can customize a retention period for replication and keep up to 28 restore points for every VMware VM replica. When failing over to a replica, Veeam Backup & Replication chooses the latest restore point by default. However, you can specify any earlier replica state you want to roll back. This might be helpful in case of a software malfunction that corrupted the latest replica restore point, which means you may need to fail over to the previous good restore point.
Deciding on the next step
After you commit failover, the VM replica takes the whole workload and replaces your corrupted production server. Its performance depends on the configuration of your DR site. If there’s a lower performing storage or insufficient bandwidth, users may experience latency in their work with an application running on the VM replica. Because of this, failover in Veeam Backup & Replication is an intermediate stage, which you need to finalize. You can leave your workload on the DR site forever, if there are adequate resources, and substitute the initial VM by performing a permanent failover. In this case, Veeam will remove all corresponding restore points (VM snapshots by nature) and exclude the original VM from the replication job, so that no changes continue to affect your new production VM born from the replica.

If your DR site doesn’t have enough resources and permanent VM failover is not an option, you can get back from running a replica to the original VM. When the issues on your main site are resolved, perform a failback operation. Veeam Backup & Replication automatically synchronizes both replica and original VMs for changes and allows you either to fail back to the original VM location or chose a new destination. The amount of data transferred during failback is intelligent in the way that it only transfers what has changed since the failover event. This can be a big time-saver!

Working with interdependent applications
The majority of critical virtualized applications are interoperating with other services in your environment. For example, Microsoft Exchange, Active Directory and SQL can be interdependent with a domain controller, DNS and DHCP servers. The availability of interdependent applications is contingent upon maintaining these correlations. In case of a major failure, you need to restore the entire group of these servers and boot each sequentially in order to ensure their proper performance.
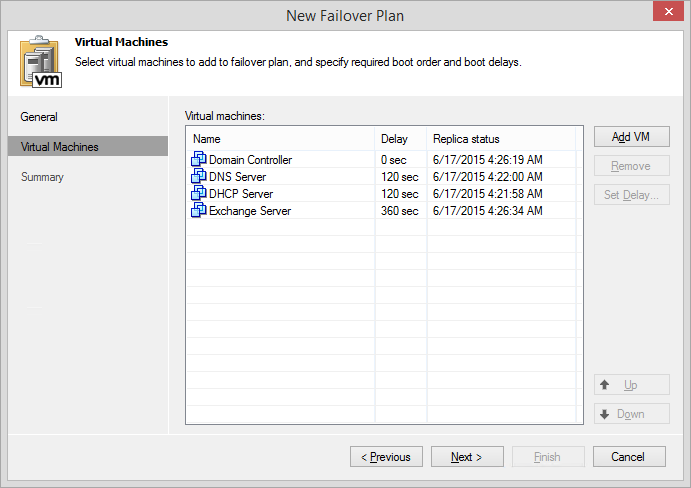
Veeam Backup & Replication v8 lets you create predetermined failover plans for a group of replicated VMs, which you need to boot simultaneously or in a specific order. In case of an emergency, you just need to initiate a saved failover plan in one click. You even can do it remotely from your tablet through the Veeam’s web UI, which is available with the Veeam Backup Enterprise Manager component installed.
Failover plans support running pre-failover and post-failover scripts. In the most common scenarios, scripts can help you stop or suspend an application, after its failover and before booting another application from the same failover plan. For example, when you are booting a Domain Controller (DC), the script can stop the next application in a queue, so you can first get a heartbeat from the running DC. You can use BAT, CMD and EXE files as pre-failover and post-failover scripts for your failover plans.
Technically, failing over to application replicas grouped into failover plans runs the same way as a regular VM failover process: you roll back to the latest valid restore point and, on failover completion, you will need to finalize the process either with permanent failover, or with a failback procedure.

Using a VM replica for data center migration and planned maintenance
You never know when your hardware, host or VM will go down, but you are always aware of planned downtimes, like data center maintenance. Veeam Backup & Replication supports planned failover scenarios that help you run your migration or maintenance operations smoothly and with minimum impact on users’ work. Planned failover moves the workload from the production VMs to the DR site via replicas before switching off production VMs without any data loss.
How does it work? You replicate the required production VMs to a new location as you normally do and run planned failover wizard when you’re ready to start migration or maintenance. Unlike the regular failover during unexpected downtime, a planned failover synchronizes all changes from your source servers that occurred since the last replication jobs run to the replicas. Once you finish running the wizard, Veeam Backup & Replication will fail over to replicas and simultaneously turn off your source VMs.

Using a VM replica for testing purposes
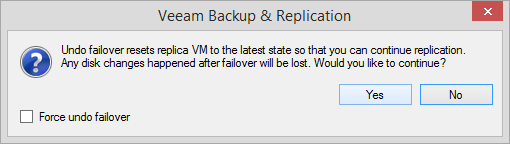
Patches, upgrades and software fixes for critical applications potentially run the risk of system crashes, which is why you should always test every change before applying it in your production environment. Veeam’s replication can help you with this, without any additional configurations or creating testing labs. Fail over to a replica and perform the required tests or apply patches on a running VM clone. Once you are done, you can safely undo failover and switch back to the production VM in its pre-failover state. All changes that occurred on the VM while it was in a failover state will be discarded and your production VM will be working in a normal mode again.
Additional helpful resources:
- Veeam Blog: Replication, backup or both?
- Veeam Blog: How to optimize replication traffic with Veeam
- Veeam Help center: Technical documentation for Veeam’s replication
- Recorded webinar: SureReplica – put your replicas to work