Veeam Kasten for Kubernetes Performance Troubleshooting Guide
| KB ID: | 4625 |
| Product: | Veeam Kasten for Kubernetes |
| Published: | 2024-06-14 |
| Last Modified: | 2024-06-14 |
Purpose
This article documents two of the most common performance tuning settings for Veeam Kasten for Kubernetes.
Veeam Kasten for Kubernetes uses helm parameters, which can be tuned to adjust performance. The default settings should suit most environments. However, in complex environments, administrators may want to tune the execution control parameters to improve performance and solve various execution issues related to system resource utilization. This guide will cover the most frequent cases seen in complex environments.
Note: When tuning the system, it is important to rely on the metrics Veeam Kasten for Kubernetes exposes. For many performance-related metrics, graphs are visible in the bundled Grafana instance. Make sure that Grafana and Prometheus are enabled (they are enabled by default).
Solution
Scenario 1: Veeam Kasten for Kubernetes takes a long time to pick up an action
Possible cause
Not enough workers to pick up actions new actions due to existing K10 worker load.
Related Helm settings
-
services.executor.workerCount
-
executorReplicas
Possible solutions
-
It is possible to tune services.executor.workerCount to increase the number of workers per executor instance
-
It is also possible to tune executorReplicas to increase the number of executor instances
Both approaches have their pros and cons. Increasing the number of workers per executor instance will not increase the resource consumption in the cluster, but at the same time may hit the limitations of the executor pod. Increasing the number of executor instances will, on the opposite, consume more resources in the cluster, but will not hit the limit inside the executor pod.
Tuning Impact Analysis
To understand the impact of the changes, it is recommended to check the in-built Grafana Dashboard. Using the Executor Worker Load graph, it is possible to observe the total number of workers (worker count multiplied by the number of executor instances) over the time and the worker load (how many workers are currently in use).

Common pitfalls
-
Setting services.executor.workerCount and executorReplicas values below their default is not recommended and can have a negative impact on Veeam Kasten for Kubernetes performance.
-
Increasing services.executor.workerCount and executorReplicas values much higher than the average worker load may increase resource consumption in the cluster without any real benefit.
-
Even if the Executor is picking up the task, it may hit the rate limiter limitations, and the task will be paused until it will be allowed to run by the rate limiter, this is covered in the following section.
Scenario 2: Actions are picked up quickly, but execution takes a long time
Possible cause
Rate Limit suspended actions due to too many of the same concurrent operations.
Related Helm settings
-
limiter.genericVolumeSnapshots
-
limiter.genericVolumeCopies
-
limiter.genericVolumeRestores
-
limiter.csiSnapshots
-
limiter.providerSnapshots
Possible solutions
-
It is possible to tune above mentioned settings to increase rate limit limits.
-
Distribute the execution of operations over time to avoid running them simultaneously.
Tuning impact analysis
To understand if RateLimit limits operation, it is recommended to check the in-built Veeam Kasten for Kubernetes Grafana Dashboard.
Execution Control | Rate Limiter - %operation%

Common Pitfall
- Increasing rate limit values can lead to overloading cluster with high amount of heavy concurrent operations.
More Information
Additional Useful Graphs for Troubleshooting Performance Issues
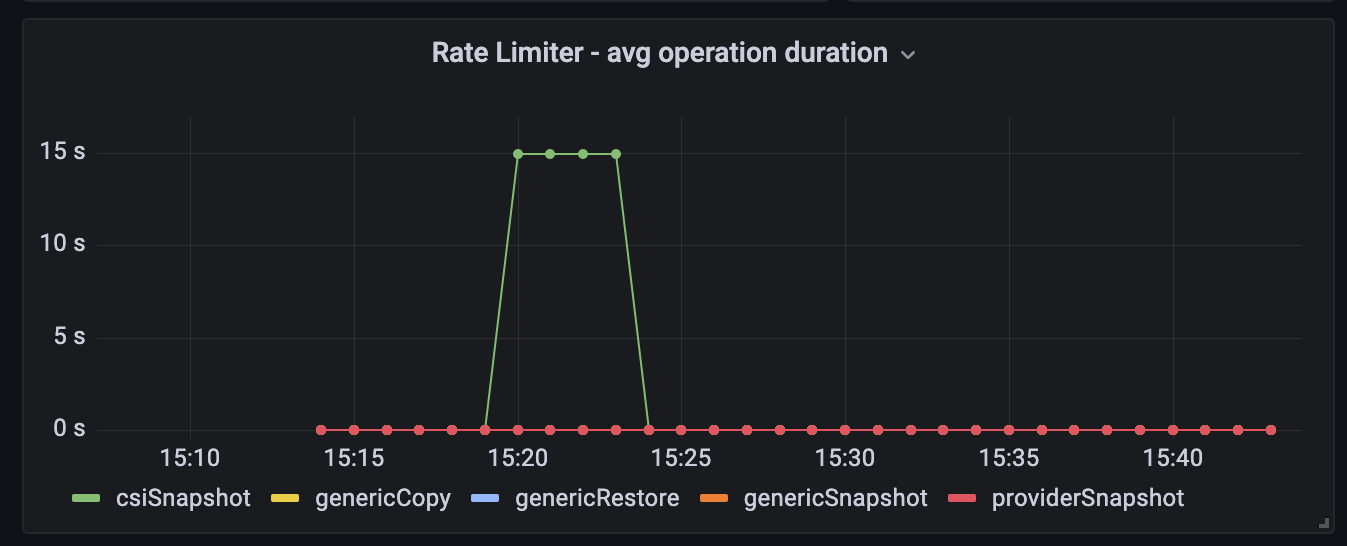
- Execution Control | Rate Limiter - avg operation duration
Can provide more information about rate limiter behavior. This can be useful over a long time period to track the trends.
Many pending tasks + low duration = many operations started
Many pending tasks + high duration = operations are in process for a long time
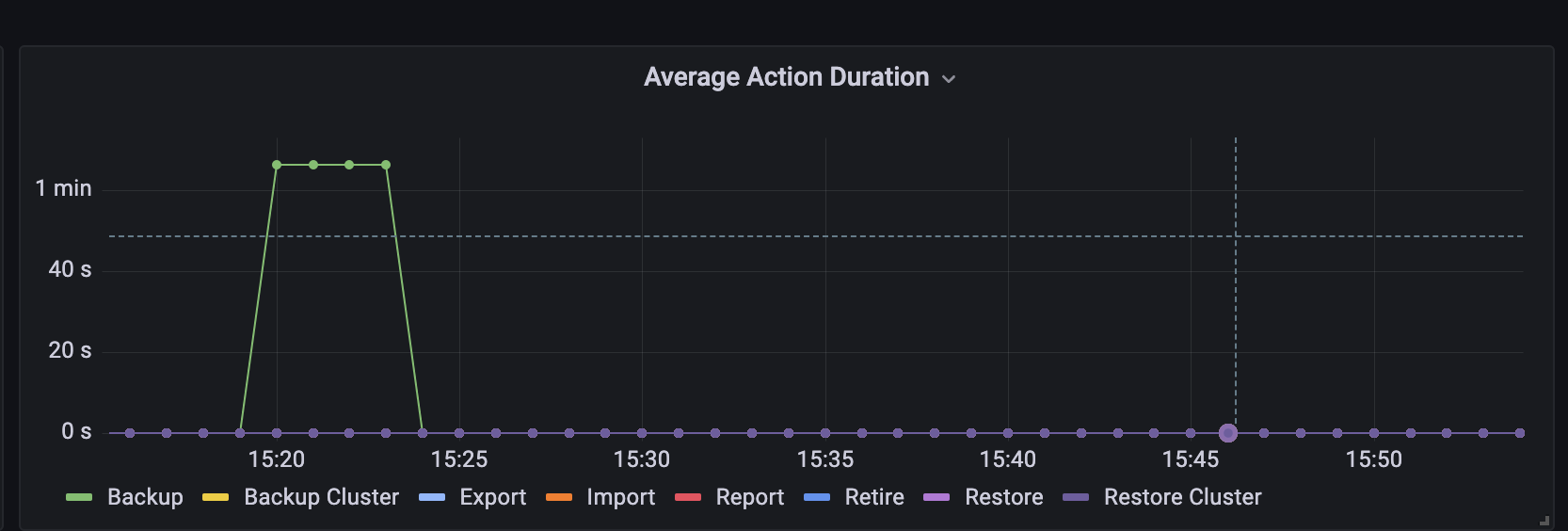
- Execution Control | Average Action Duration
Displays average time consumption for different types of actions. This can be useful over a long time period to track the trends.
For example:- Average export duration dramatically increased on a certain day - possible network problems that day(?)
- Average backup duration is noticeably increasing every day - possible user backup some unwanted data like logs data(?)
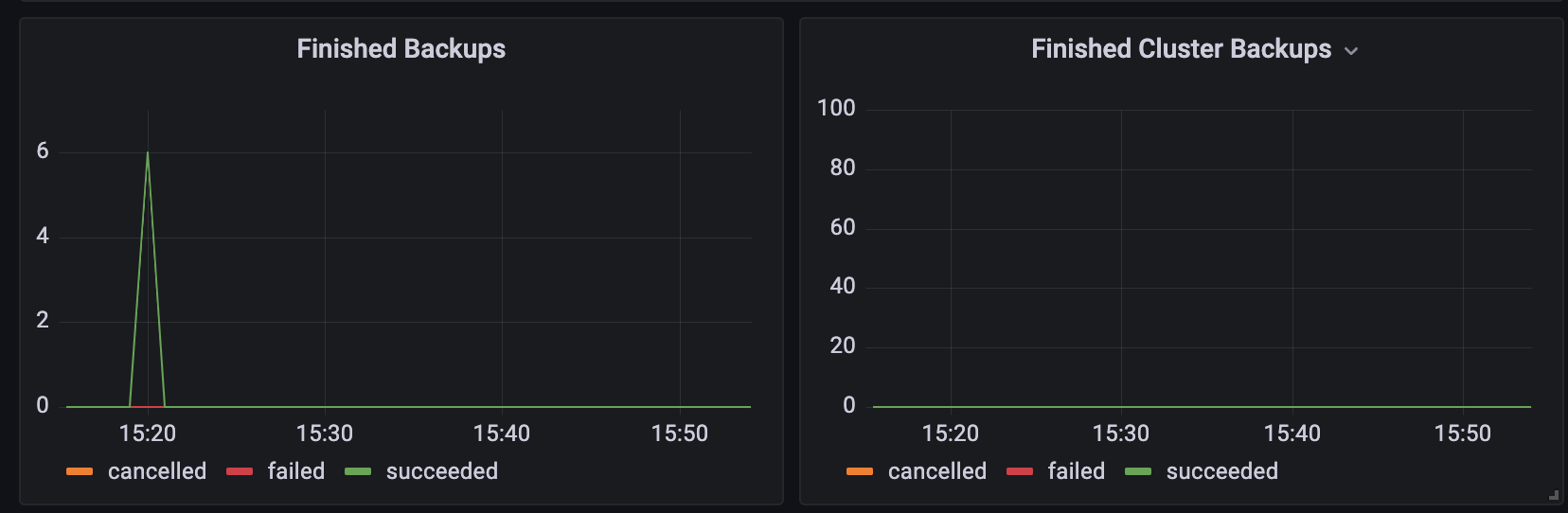
- Execution Control | Finished %actions%
Displays finished actions by status on the timeline.
Some examples of how it can be useful- Peaks of finished jobs + huge Average Action Duration value indicates that it is advisable to distribute the execution of operations over time to avoid running them simultaneously.
- Failed actions can correlate with some infrastructure issues.
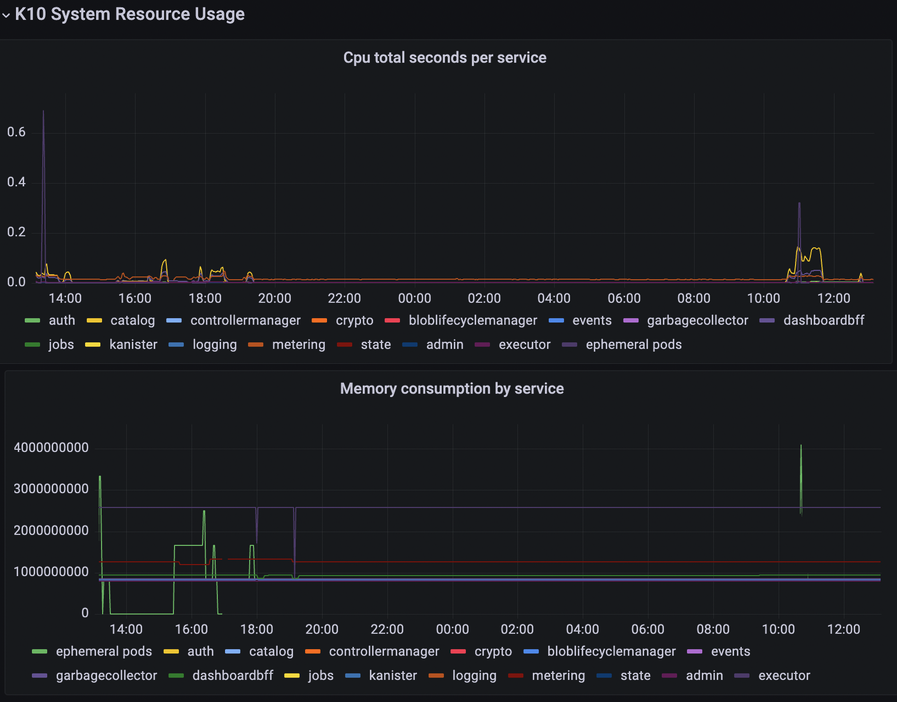
- K10 System Resource Usage| Cpu total seconds per service/Memory consumption by service
Understanding the dynamic utilization of resources can help investigate performance problems. By monitoring resource usage, insufficient resource availability for the cluster can be identified or suspicious resource usage after recent changes can be detected.
Additionally, analyzing resource usage per service can help fine-tune pod limits/requests. For example, if a system slows down due to a particular service working close to its limits, it may be necessary to increase the limits/requests for that service if there are enough resources available in the cluster.
Examples of such configurations include gateway.resources.[] and genericVolumeSnapshot.resources.[]
If this KB article did not resolve your issue or you need further assistance with Veeam software, please create a Veeam Support Case.
To submit feedback regarding this article, please click this link: Send Article Feedback
To report a typo on this page, highlight the typo with your mouse and press CTRL + Enter.
Spelling error in text
KB Feedback/Suggestion
This form is only for KB Feedback/Suggestions, if you need help with the software open a support case