Previously, we’ve gone over design, performance and backup target considerations. Let’s continue our discussion with thoughts on network and restore targets.
Network consideration
The next thing to look at is the network. Ideally, you’ll have 10 Gbps or better in your backup targets (I normally leverage dual 10 Gbps). On the backup source, you can get away with less but then you really need to leverage some form of bandwidth aggregation such as NIC teaming with LACP or SMB Multichannel. You could use 4×1 Gbps LOM ports for this.
As backups source to backup target tend to be a “many-to-one” situation, this can work, but avoid this at the backup target itself. Likewise, parallel restores from a backup target to multiple restore targets (quite often the backup source) is a “one-to-many” game.
You can have multiple backup jobs for multiple Hyper-V hosts / LUNs write to the same backup target. Assume you have 10 hosts with 4×1 Gbps aggregated bandwidth running one or more backup jobs and you’ll see that if you can fill those, you can easily fill one 10 Gbps pipe on the backup target.
If you are leveraging SMB shares as backup targets, SMB multichannel does its work just fine, potentially helped by SMB Direct if you have RDMA capable NICS configured end to end. Today, many Hyper-V cluster designs leverage 10 Gbps RDMA-capable NICs already so you can use them. The Veeam data mover doesn’t leverage SMB however. Keep that in mind when designing your solution.
Also note that with Windows NIC teaming the switch independent mode allows sending from all members but only allows for receiving on one member. If you want optimal bandwidth in both directions for a single process, you are better off leveraging LACP, but then you need to have multiple restores to the same host. Bandwidth aggregation comes with conditions and is not the same as a bigger pipe. Keep this in mind during design as you look at your use cases.
Depending on your network environment, you can leverage Windows-native NIC teaming in LACP or Switch Independent mode and/or SMB Multichannel. The latter is useful when you use SMB file share and want to leverage SMB Direct in your environment. All these possible configurations deserve one or more articles by themselves.

What’s important here is that you want a lot of bandwidth and low latency to provide Instant VM Recovery with the best possible performance for mounting the virtual disks, accessing data and copying data over. Remember, you might very well be doing multiple recoveries in parallel. During that process, backups jobs might still be running. As all networking today is full duplex, you don’t need to worry about the incoming traffic hindering the outgoing traffic. When bandwidth is plentiful, it’s compute and storage that determine the speed. When you have designed your backup solutions network well, you most often will find that you can leverage that for your (Instant) VM Recoveries without the need for anything different or more.
Restore target considerations
Normally our storage arrays for virtualization are the best storage you’ll find in the datacenter. So, you could think you have nothing to worry about. While we would all love to have “All NVMe Arrays” where you can go crazy with huge random IO and never notice even a slight drop in performance due to lack of IOPS or too high latencies. The reality is that this is probably not something you have. So, let’s look at some of the options you should optimize.
Restore to Hyper-V production hosts directly to the production LUNs
Even when you have a high-performance storage with read/write caching or a tier 1 storage layer, you have to be careful not to fill up the tier 1 storage layer so you’re not falling back to the lowest common denominator in the array. This can have a profound impact on the workloads running on that storage array. This can easily happen when you push large amounts of data to it as fast as you can. Normally you see this happen during storage migrations and you protect against it by avoiding tier 1 for such operations. This is something to consider as well during massive VM restores. Maybe you’ll want to restore to separate LUNs with a different storage profile for example. The restored virtual machines can be storage live migrated to the production CSV at a controlled pace and be made highly available again in the cluster via storage live migration. Depending on your storage array’s capabilities regarding IOPS and latency, this can work fine.
Restore to Hyper-V production hosts with local SSD/NMVe disks
Another approach that is cost-effective and very efficient is to have a Hyper-V node that has some local SSD or NVMe storage. The size depends on how many virtual machines you want to restore in a given time frame and how large those VMs are. But the quality doesn’t need to be premium as I hope you’re not doing restores all of the time to your Hyper-V hosts. This means it isn’t that expensive to set up. You could have one SSD in every cluster node, in just one or in a couple. The more you have, the smaller (cheaper) the SSD/NVMe can be and the more the workload is spread across different hosts. The instantly recovered virtual machines can be moved to the normal production CSVs leveraging storage live migration at a more relaxed pace and be made highly available again.
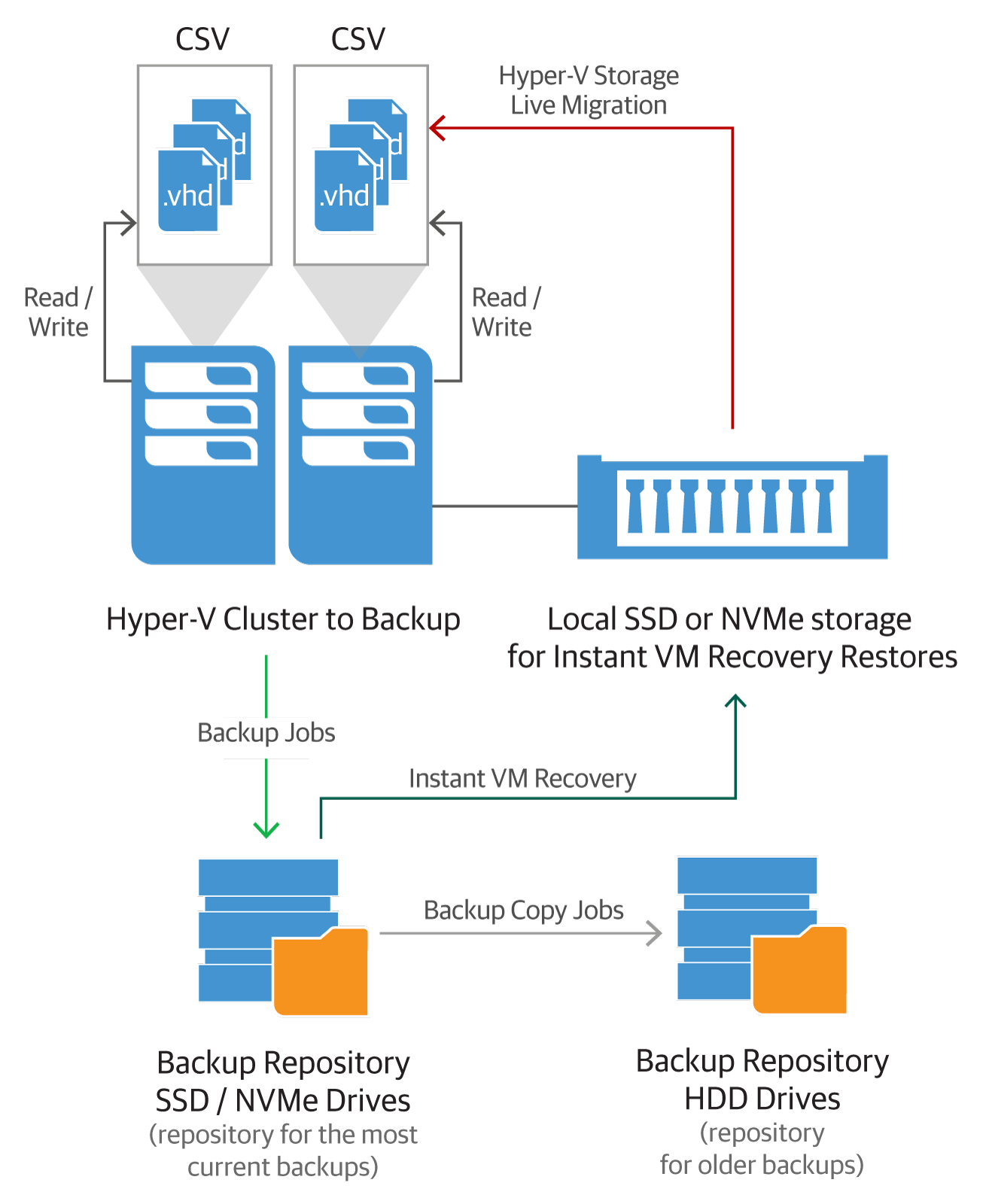
A possible design. You can mix and match the options discussed above to achieve a solution depending on your needs and environment.
Restore to dedicated Hyper-V restore hosts with local SSD/NVMe disks
Instead of having some fast, local storage in the Hyper-V hosts themselves like above, we you can also opt to use one or more separate (dedicated) restore host for recovery. This avoids any resource impact on the production Hyper-V hosts in the cluster. In this case you really might want to consider some NVMe disks to ingest all the restores elegantly. Testing will show how well such a restore host can scale up (CPU, network, storage).

If you need more, you can scale out. In this case you’ll leverage the Shared Nothing Live Migration after the restore to get virtual machines back to the production nodes. This means setting up additional security configurations to allow for this. For the networks side of things, you can leverage your SMB Multichannel and SMB Direct capable CSV/Live Migration / S2D Hyper-V networks for this. Please note that storage live migration is not the fastest process. It will take a while to get the restored virtual machines moved back to the CSVs. The good news is that they are up and running during the process.
Conclusion
Depending on where the bottleneck is in your environment (source, fabric, target) you’ll have to decide what options you choose based on your needs and economics. You can do this perhaps only for a subset of VMs that are important to the business or for customers that are willing to pay for such a service and/or as a way to differentiate yourself from the competition.
No matter what design you end up with, you can achieve your primary goal. That is to have very fast virtual machine restores to get the customer or your services back up and running as soon as possible. When that is achieved, you can storage or Shared Nothing Live Migrate the virtual machines back to the redundant, high available storage of the cluster at a more relaxed pace to make sure the workloads are available again. The last thing to do then is to make sure those virtual machines are still or again protected by Veeam, just in case the day arrives we need to restore again.
While the Veeam Backup & Replication resource scheduling will optimize the use of resources the best it can, you can help by providing adequate resources to make sure the process goes smooth and fast.
This article has given you some ideas on how to deliver super-fast restores to your customer or business units. To what extent you implement such a solution will depend on the economics of your wants and needs. That’s an exercise I leave to the readers for their environment. Remember that a small setup like this would help deliver great results to a mission-critical subset of virtual machines without breaking the bank while a larger scale-out design can help deliver top notch SLA for larger environments. You might need it or not, if you think you do, I hope you found this useful to think about tackling the challenge.
Afterword
If you happen to run any of these storage systems, you can also leverage an advanced integration with Veeam for highly-efficient restore of guest OS files, application items and entire VMs from a storage snapshots with help of Veeam Explorer for Storage Snapshots.