For today’s enterprise, IT management of backup storage is an enormous and expensive proposition with no relief in sight as data continues to grow. This problem is made worse as legacy backup solutions struggle to address this issue in an efficient manner, causing backup storage management headaches with too much management overhead and too many pockets of unused, wasted storage.
We need a better way. A way to simplify backup storage management in the enterprise – and dramatically reduce the associated IT workload – while lightening the impact on data protection budgets by reducing backup storage hardware spending.
Here at Veeam we’re constantly innovating, and today we’re introducing an exciting new capability that promises to revolutionize the way you manage backup storage today. Veeam’s new Unlimited Scale-out Backup Repository overcomes legacy backup storage management challenges by creating a single, scalable backup repository from a collection of heterogeneous storage devices. This effectively creates a software-defined abstraction layer through which backup storage can be more efficiently managed and utilized, radically simplifying backup storage and backup job management.
How does it work, you ask? Read on for all the details.
Backup storage management today – an IT administrator’s headache
Do you recognize this view? These are all backup repositories, and this picture is something a lot of our customers have to live with.
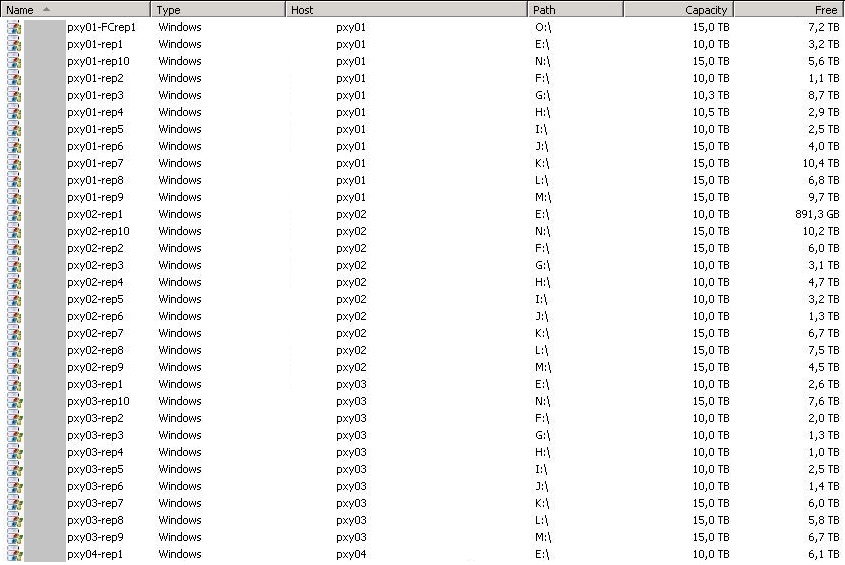
What causes this? The most common reason is using more than one physical storage device as a backup target (for example, backing up to internal disks of physical servers is a popular backup storage solution). And in other cases, storage devices may simply have limitations on the maximum volume (LUN) size. One way or the other, the majority of our customers use more than one backup repository, as even the smallest environments quickly outgrow the original backup target – which is never just thrown away.
This situation forces most of our users to create at least the same number of backup jobs as backup repositories. They don’t necessarily want to – but they have to – create and manage dozens or even hundreds of jobs to be able to consume their backup storage capacity.
And, there is another problem that is not immediately obvious: if you look at the Free column, you will see LOTS of wasted disk space sitting there. Indeed, we have to be really “pessimistic” with the job placement today to account for future VMs growth – otherwise, you are basically committing yourself to random backup failures due to lack of repository disk space, and constant job redesign. And you pay for this, quite literally, by having to buy additional backup storage – when 30% or more of your existing storage capacity remains unused, simply waiting to accommodate future growth.
Are you tired of having to choose which backup repository to target backup jobs to in order to best utilize your available storage resources? Do you want to stop this constant backup job micro-management once and for all, and skip your next backup storage purchase by simply better utilizing your existing storage? If yes, read on ;)
A new species of Backup Repository
Picking the right backup storage solution has always been something of a matter of survival, like what is seen in nature: based on the existing environment, customers or their consultants had to figure out which solution was the best for a given scenario. Sometimes a screaming fast storage array, sometimes a huge system capable of holding a vast amount of restore points, sometimes a deduplication appliance, and so on.
Compared to nature however, those systems are lacking one important feature: evolution. Once selected they usually do not change their behavior and their characteristics. An all-flash array is not going to be cheaper than a dedupe appliance in the short future, a disk array will never be faster than an all-flash array, a deduplication appliance will never be able to start a VM from a backup file like a storage array. Each choice has pros and cons, and designers have to carefully choose a solution because that solution has a cost, and its lifecycle has to be long enough to pay back the acquisition cost. No one wants to buy additional backup storage after a few months because their initial choice was wrong In this modern world, we are all facing the amount of data doubling every year, As technology evolves, making the correct decision is even more of a challenge.
Enterprise customers have to deal with growing amounts of data, and while this happens they also have to guarantee to their stakeholders a tight control over costs, storage capacity, backup windows and management costs associated with those systems. Not an easy task. Some of those issues have been addressed by Veeam with the introduction of Backup Copy Jobs and the reference architecture: a fast and small first tier for fastest backup and recovery, and a large and cheap (per TB) second tier to store backup copies to extend the retention on a budget. Still, the management of those repositories had to be addressed: initial selection, space consumption over time, repurpose and retirement.
The Scale-out Backup Repository is a great new feature that will arrive in Veeam Availability Suite v9 to address exactly these issues, and to offer customers a new way to manage their backup storage.
In a sentence, a scale-out repository will group multiple “simple” repositories into a single entity which will then be used as a target for any backup copy and backup job operation. As simple as it sounds, it will give users many awesome new opportunities. I’m pretty sure your mind is already thinking of creative ways to leverage this awesome feature…
Global Pool
Scale-out backup repository is an extremely easy way for small and large customers to extend repositories when they will run out of space: instead of facing long and cumbersome relocations of backup chains (which can become pretty huge in large customers), users will be able to add a new extent (that is a “simple” backup repository) to the existing scale-out repository. All existing backup files will be preserved, and by adding an additional repository to the group, the final result will be the same target for backups getting additional free space, immediately available to be consumed.
This capability, especially when combined with another great feature coming in v9, per-VM backup chains, also means that you can finally have a single job protecting your entire environment, even if you have thousands of VMs. Just point that job to a scale-out repository backed by a large number of extents, and stop worrying about individual repository capacity management and job size planning forever – all without sacrificing backup performance! Unlike with competing storage pooling technologies, a single job will leverage all available extents at once, thus maintaining performance levels that previously required creating large amount of backup jobs and running them concurrently.
Leverage Your Storage Investments
Scale-out Backup Repository is not just a group of repositories acting like one. Said this way, it sounds like any other scale-out solution: you add more nodes, and the system starts using the additional space and compute capacity. This is true also for our scale-out repositories, but it’s just a part of the story: Veeam is not a storage company, it’s the software solution that consumes the storage that a customer chooses based on his needs in terms of features, performances, space, cost. Thanks to scale-out repository, customers will be able to mix and match different storage systems – any backup target supported by Veeam: Windows or Linux servers with local or DAS storage, network shares and even deduplicating storage appliances. You have many small chunks of free space spread around multiple servers or filers? Add all those in a new scale-out repository, and immediately you will be able to put that free space that was left unused before to the good use. Stop buying storage and fully leverage the capacity on-hand!
But even more importantly, with Scale-out Backup Repository being a software-defined storage technology, sitting on top of the actual storage devices means that every single feature of any storage solution will be preserved: for example, a dedupe appliance will still be able to offer great data reduction results and enhanced performance by leveraging their unique APIs (such as EMC Data Domain Boost, HP StoreOnce Catalyst or ExaGrid Accelerated Data Mover). Yes, you got it right: you will be able to mix and match any kind of repository that’s available in your environment, or the one you are planning to acquire – and still leverage their advanced capabilities. Unlike other general-purpose scale-out storage solutions, we do not limit you to servers with local disks.
This solution yet again underscores Veeam’s primary design goal of being completely hardware and storage agnostic. While other enterprise backup vendors only support specific storage platforms – or worse yet, want you to buy their own storage appliance, forcing you to acquire even more storage resources (except not even general-purpose this time) – Veeam takes completely the opposite route. We say – leverage the storage you already have sitting in your data center, and don’t pay anyone else more until you have fully exhausted those existing resources.
Storage Aware Placement
Every type of backup storage is different, and scale-out backup repository is designed with this in mind. For each extent, you will be able to assign it a “role”: with just a few mouse clicks, you will define if a repository of the group will accept full backups, incremental backups, or both. Start thinking about the endless possibilities: a scale-out repository could be created, in its most simple form, by grouping multiple repositories with different characteristics, but still be configured to seamlessly leverage strengths of the particular storage devices included.
Take the example of the transform operation in a Veeam backup: when it happens, two I/O operations are consumed to merge the oldest incremental file into the full backup file. Many low-end backup storage systems suffer from this random I/O, and customers end up preferring active fulls, thus reducing I/O’s but losing the advantages of the forever incremental backup. Now, imagine adding another simple JBOD to the backup repository; scale-out backup repository can make them act in a completely different, and better way. By assigning incremental backups to one extent and fulls to the other, when a transform happens one I/O (read) out of the two I/O operations is now performed by the repository holding the incrementals, while only one single (write) I/O is left to the one holding the full backups. Without any addition of flash, cache or any other mechanism, scale-out backup repository is immediately improving the transform operation performance by at least two times. Not bad!
But then, start thinking about a collection of specialized extents rather than an army of small clones like those JBODs: what about combining a crazy fast all-flash array to ingest daily incrementals at high speed, together with a generic dedupe appliance to hold multiple GFS full backups? You are combining two completely different solutions, leveraging the best capabilities of each, and removing their limits at the same time.
Every given type of storage, even the most advanced ones, can be a great fit in one scenario – and a bad investment in the other. Scale-out backup repository will give customers complete freedom of choice, while preserving the underlying capabilities of any storage that a customer could select, making the combinations will endless!
A Storage Cloud
Thanks to the abstraction layer created by scale-out backup repository, the backup administrator can become the “storage cloud provider” of a self-service solution where users are free to set up their own backup jobs without having to think what storage to target, nor doing complex calculations planning backup job size and retention to ensure that their job will fit into the given repository.
Instead, the backup administrator can just set up a single scale-out backup repository. This way, users will only see one repository to choose from (instead of the dozens of underlying ones); and will be able to select it as a target for their jobs in a complete self-service fashion. After that, the scale-out backup repository will start to consume the available extents based on their policy and the amount of available free space. As in any proper cloud-like solution, the scale-out backup repository will allow a complete separation of duties between providers and consumers.
In nature, the way to survive is to evolve. The Veeam Scale-out Backup Repository will allow you to evolve your backup target to quickly adjust to a fast changing world, without wasting any backup storage investment you’ve already made.
To me, this sounds incredibly cool. Doesn’t it?
Need more information? Check out our free resources:
 White Paper – A Deep Look at Scale-out Backup Repository
White Paper – A Deep Look at Scale-out Backup Repository
Get a deep understanding of Veeam’s Scale-out Backup Repository functionality and configuration. With this white paper, you will learn about recommended data locality policies, deployment and performance optimization. Additionally you will see some best practices for Scale-out Backup Repository integration in existing large-scale environments.
 Recorded Webinar – Simplifying Backup Storage Management with Unlimited Scale-out Backup Repository
Recorded Webinar – Simplifying Backup Storage Management with Unlimited Scale-out Backup Repository
Watch the recorded webinar on Veeam’s Scale-out Backup Repository configuration and usage. This will demonstrate how to choose better data locality policies, automate backup job management and fully leverage your storage capabilities.