Migrating and/or replatforming can be intimidating. And for good reason — there are often many complex and disparate systems with varying levels of tech debt, multiple teams, stakeholders, and business units involved. They need to be consulted, assist with pre- and post-migration activities, and often have aggressive timelines with little flexibility in terms of downtime or maintenance windows.
And all to say, having personally been involved in a number of large replatforming projects in my career for major enterprises (banking, healthcare, oil & gas) and government customers (U.S. Federal, state, and local), it’s often a thankless job. Best case scenario, customers and/or business users aren’t impacted or don’t notice the transition either during or after the fact. Often, months or even years of effort are devoted to ensuring a smooth and timely transition to the new platform — not dissimilar to the millions of man-hours devoted to updating or patching systems ahead of Y2K.
And as daunting as it may all sound, the best way to approach something as big or complex as a large migration is to break it down into smaller pieces.
The aim of this post is to provide you not with a comprehensive A to Z guide on how to migrate (as there are entire books written on the subject), but rather a bit of guidance and insight based on my personal experience; knowledge of the relevant technologies; and some important lessons learned.
Industry Challenges and Considerations
It likely won’t come as a surprise to say that organizations are facing challenges from multiple angles at the moment when it comes to technology, costs, speed-to-market, and competition. Below is a non-exhaustive list of challenges we witness with many of our existing customers and prospects.
Application Modernization
First and foremost, IT departments and development teams across the board have felt the steadily building pressure to modernize applications, and to shift from an infrastructure-centric to an application-centric approach to IT and application architecture. As recently as a mere decade ago, containers and microservice architecture were considered a novelty or academic exercise. Today, however, we are witnessing more and more applications and organizations embrace cloud-native architecture for greater portability, automation, and development velocity. Model/View/Controller architecture is out, and microservices and auto-scaling are in.
Expectation of Velocity
It seems everything is an app these days — whether on our mobile devices, smart TVs, car infotainment, or cars themselves. We, as consumers, have come to expect (for better or worse) frequent and nondisruptive updates and new capabilities in our existing products; that expectation has extended to our internal corporate or organizational systems as well.
And, as you can likely gather, this ability to support increase in velocity has real competitive advantages for organizations. A hypothetical example: Two competing companies, Acme Systems and Nadir Corp, function in an industry in which each shares 50% of the market. If Acme Systems successfully embraces a more flexible and agile architecture earlier or more effectively than Nadir Corp, it is able to innovate more quickly, achieve faster time-to-market, and deliver customer satisfaction at a higher cadence. Acme Systems is going to quickly win over Nadir Corp customers while retaining their existing business. So, while it could be characterized as a bandwagon argument, to your mother’s chagrin, sometimes it does make sense to jump off a bridge if all of your friends are doing it.
Escalating Costs
It’s no secret that there have been some rather large acquisitions and consolidations in the technology industry of late. And while it doesn’t always lead to an increase in costs (e.g., licensing and support), it very often does. The cost to run the business systems has ballooned 3-5x in many cases, drawing into question existing long-term vendor relationships and how “locked-in” your organization may be. It’s all but guaranteed that when evaluating new pricing, some of these newly consolidated organizations are taking into account their lock-in and existing skillset in a particular set of technologies. Add in increasing capital costs (e.g., RAM), we’re behooved to leverage existing assets, such as storage and servers for whatever platform we choose to pursue.
Hybrid and Multi-Cloud
Whichever approach we choose, we need to ensure we don’t lock ourselves into or out of a specific software or cloud. We run the risk of having to re-do the exercise all over again should our new chosen vendor(s) or cloud provider(s) later decide to raise costs. We also need to be cognizant of failure domains, availability, peak-load sizing, and IT sprawl, ensuring we’re not spending unnecessarily to run “zombie workloads” or investing too much in on-premises hardware to size for peak load. Open source software can be a big help here, but we need to ensure that we can achieve stability, support, and interoperability in our chosen architecture.
Emerging Workloads
When choosing to replatform, we want to ensure we’re able to support existing workloads without kicking the can down the road to where later we won’t be able to support emerging workloads, such as Artificial Intelligence or Machine Learning. As it so happens, many patterns have already emerged where Kubernetes is the chosen platform for these new technologies, due to its ability to support diverse workloads, scale up and down easily, and efficiently allocate workloads to infrastructure.
Threat Landscape
AI isn’t only benefiting organizations and consumers — it’s also helping to lower the barrier for threat actors to design and execute sophisticated attacks, whether it’s data exfiltration, ransomware, or political hacktivism. Whichever platform or architecture we choose must have a security posture equal to, or greater than, our current platform to help better defend ourselves and our critical business data against attacks.
Preparing to Migrate
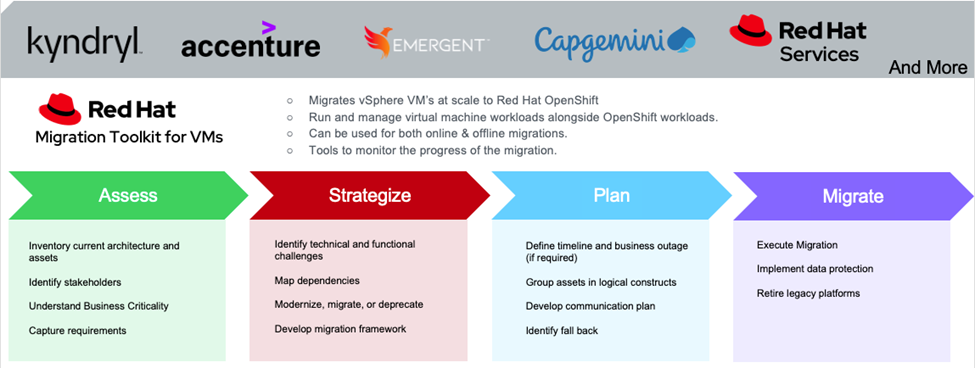
While by no means a foregone conclusion, we are going to assume that you and your organization have conducted the due diligence and concluded that a replatform makes sense. Choosing a new platform is no easy task; in the interest of time, we won’t delve too deeply into the subject, although we encourage you to have a watch of my colleague Michael Cade’s Hypervisor Hunger Games webinar. For the purposes of this blog, we are going to assume that you and your organization have identified Red Hat OpenShift as the chosen target platform — perhaps initially just for virtualization workloads, but with plans to modernize to a hybrid approach, where existing applications are either re-architected or suitable alternatives identified that can be deployed as containerized workloads.
Having decided on OpenShift with OpenShift Virtualization, it’s important to identify what existing tools, processes, and technologies can be leveraged for the new platform and which will need to change. This could include deciding to leverage existing hardware or purchase all new equipment, uplifting integrations such as your organization’s ITSM for infrastructure provisioning, and evaluating your current backup and disaster recovery tooling. You must determine whether it can be employed on the new platform, or whether a new or supplementary solution is appropriate. Additionally, it’s important to begin preparing teams and practitioners with training and resources to learn how to design, build, migrate, and operate an OpenShift solution. In my personal experience, working for a large Global System Integrator, the success of the new architecture and the overall migration process was almost always dictated not by the chosen technology or architecture, but rather by how ready the organization’s operations teams are to manage, troubleshoot, and scale the new platform. In some cases, this required months of training across teams and disciplines, sometimes resulting in organizational realignment to better meet the needs of the new platform.
Another common area that has a significant impact on the success or failure of the replatform project is effective communication. Organizations that opted for a well-defined, thorough, and continuous communication plan often had much better success relative to those that attempted a “fly by night” cutover operation. Having open and honest communication among the technical and business teams is incredibly important, to establish trust, build understanding, and help prevent any unwelcome surprises when the migration occurs.
And probably the most important pre-migration step is performing a thorough inventory of the assets to be migrated, including identifying VMs, their dependencies, their resource requirements, their criticality to the business, and any application-specific requirements to ensure minimal impact during migration. Data, network, and shared services considerations are especially important, as workloads often cannot be simply lifted and shifted without some configuration changes among shared services (e.g., IPAM and DNS, Active Directory, load balancers, etc.).
We’d often perform multiple interviews with varying staff, including application owners, business stakeholders, and database administrators to get a full picture of what the workloads we were migrating were, and how to best migrate them. We would define pre-migration and post-migration test plans and have well-defined rollback plans in the event that migration failed or business impact grew beyond a predetermined threshold.
We’d typically group migrations in waves, starting with low-impact workloads, such as development, testing, or staging environments, then working incrementally toward more critical workloads. Wave sizes often varied, typically starting small, then gradually growing and eventually shrinking again as we approached the most critical workloads. Working with the business, we’d identify what could be migrated cold versus live. For the most critical business applications, we’d typically group scaled-out components across platforms temporarily, where part of the workload would run in the traditional environment and part of it in the new one.
Best Practices for Migrating from VMware vSphere to Red Hat OpenShift
After months of planning, interviewing, analyzing, testing, and preparing, we’d begin our migration. There are a number of ways to migrate; however, the cornerstone to help simplify and automate migration is the free Red Hat OpenShift Migration Toolkit for Virtualization Operator. Using MTV, VMs can be grouped per their wave migration plan and migrated per their availability requirements (e.g., cold versus warm migration).
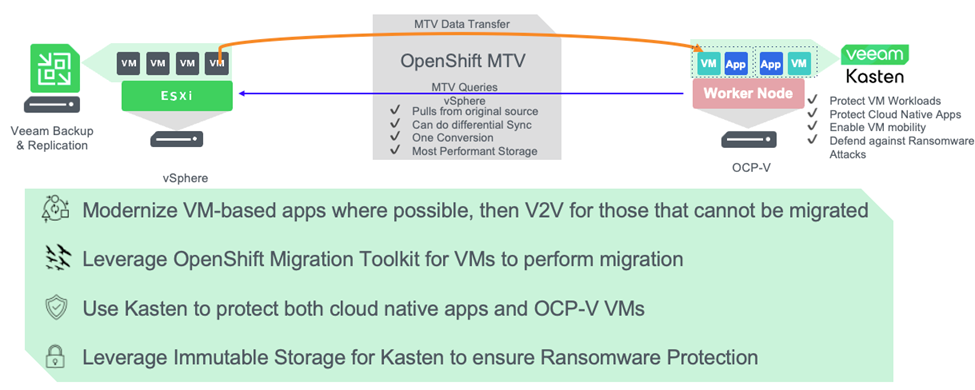
In no particular order, here are some key best practices that we observed to ensure a smooth migration with minimal business impact:
- Cull the herd — identify any VMs that can be decommissioned or consolidated down to prevent having to migrate unnecessary workloads. In the case where a VM’s purpose or owner cannot be identified, and after exhausting all other channels, a good “catch-all” solution we’d often use would be to power down the unknown VM on a Monday evening after the close of business and leave it powered off overnight. We’d typically know first thing Tuesday morning via a help desk ticket if that VM needed to be migrated and what purpose it served. Additionally, identify any off-the-shelf software that may be running a VM today, and that can be easily transitioned to a containerized, cloud-native architecture. Things like load balancers, web servers, and proxies are often good examples of workloads that may be VMs today but can easily be transitioned to their containerized equivalent on the new platform.
- Application and database replication can significantly lighten the load — in the case of workloads like SQL servers or Active Directory, one approach we would often take would be to deploy a net-new server on the new platform and then configure that new server to be an additional node in the cluster. Then the application would take over the role of migrating data without any downtime, and we could decommission the cluster nodes that reside on the old vSphere cluster.
- Don’t forget the drivers — virtiO drivers and qemu tools are critical to install ahead of time, so that once migrated, the VMs can boot to their newly converted disk drives. This is particularly critical for Windows VMs. Endpoint management solutions such as Microsoft Intune or ManageEngine Endpoint Central can be very helpful in rolling out drivers and guest tools to VM endpoints ahead of time.
- Start small and scale up — as mentioned above. Define migration waves ahead of time, starting small with non-critical workloads and working towards larger and more critical workloads. Plan on having a set of small waves at the end for the most critical workloads. Additionally, we’d typically have 2-4 empty “waves” defined at the end of our migration wave plan for any stubborn workloads.
- Have a well-defined and documented rollback plan. No matter how much planning, communication, testing, and forethought are undertaken, there will be some workloads that simply fail to migrate on the first try. While disappointing (especially so when it occurs at the witching hours), these failed migrations can be handled smoothly by simply unwinding the migration and trying again at a later date. One good practical solution is to use your incumbent backup solution, which, if you’re using best-of-breed technology, would be Veeam Data Platform. In the event of a catastrophic failure where you can’t boot the original source VM, you can quickly recover via Veeam Backup and Replication.
Check out our latest webinar Mapping your Migration: Explore The Path to OpenShift Virtualization for extra guidance. And of course, if you’d like professional assistance with your migration, both Red Hat Services and our GSI partners have a wealth of experience to offer in assistance.
Post Migration Considerations
Having followed the guidance of this blog, most of the effort for the migration is front-loaded; where post-migration is primarily concerned with cleanup and decommissioning of old virtual and physical systems. Common items include ensuring IPAM is up-to-date, removing any entries for VMs that no longer exist, auditing existing security policy, and ensuring the principle of least privilege is enforced. Performance benchmarking is often a good idea to gain an understanding as to how workloads are performing post-migration and adjust resource allocation as necessary. When working for the large GSI, often the last three months of our engagements were spent authoring documentation and knowledge transfer, to ensure the new system could be maintained and scaled when needed. And of course, it’s important to implement backup and disaster recovery for OpenShift Virtualization, which leads me to the final part of this blog: Protecting Red Hat OpenShift workloads with Veeam Kasten.
The Role of Veeam Kasten in Supporting Migrated Workloads
It will likely come as no surprise that I’d highlight backup and disaster recovery in this blog; after all, we are a data-protection company. And while I’m positioning this section at the end of this piece, it really should be considered much earlier in the process — really back in the platform selection and pre-migration planning phases. Recall how we highlighted in the Industry Challenges section that some software, tooling, and processes could be leveraged in the new platform, and some would need to be reconfigured or redefined? Data protection is certainly one of them. And the good news is that no matter what path you choose or platform you select, Veeam has your back.
If you decide on Red Hat OpenShift as the best path forward to accommodate VM and cloud-native workloads on a single platform (which would be an excellent decision, by the way), you’ll likely want to consider Veeam Kasten as the means by which to protect these diverse workloads. And just like Veeam Data Platform, Veeam Kasten is a leader in the space, recently achieving “Outperformer” status in the GigaOm Radar for Kubernetes Data Protection for the sixth year in a row!
If you are an existing Veeam Data Platform customer, you can leverage your existing VBR server and backup repositories within Kasten; alternatively, it supports object lock for any S3-compatible storage. And later this year, Veeam Backup & Replication will release support for OpenShift Virtualization VMs, as an option for existing Veeam customers looking to simply lift and shift VM workloads without any need for containerized workload backup or plans to modernize applications into a cloud native architecture. And last, but not least, Kasten can fully leverage Veeam Vault as a backup target, to ensure your organization’s VM and container data are safe from ransomware attack. As for primary storage, Kasten supports any storage array or hyperconverged architecture with a CSI driver that supports volumeSnapshot capabilities.
It’s worth mentioning that Kasten is one of only a few OpenShift Virtualization backup solutions that offer block mode disk backups, allowing you and your organization to leverage the most performant VM storage, rather than having to architect around using Filesystem mode disks for your OpenShift Virtualization VMs. Furthermore, unlike other backup solutions, Kasten offers incremental backup capabilities along with built-in deduplication and encryption for VMs, helping to optimize backup and recovery performance as well as minimizing backup storage footprint.
In addition to data protection, Kasten also offers application and VM mobility, allowing you to move a VM or containerized application from one cluster to the next, even if the clusters use different underlying storage. A great example of this in the Disaster Recovery hot/warm use case highlighted in the Veeam Kasten and Red Hat OpenShift Virtualization Reference Architecture, where an on-premises Bare Metal OpenShift cluster serves as the primary site and a scaled-down Red Hat OpenShift in AWS (ROSA) cluster serves as a disaster recovery site.
Conclusion
Red Hat OpenShift Virtualization is emerging as a leading next-generation platform. With its ability to host both VM and cloud-native workloads, it can serve as a single platform for all workloads. Organizations can minimize licensing costs, consolidate operations, and better embrace cloud-native architecture — all with enterprise support. With Red Hat’s OpenShift Virtualization operator and Migration Toolkit for Virtualization, organizations can easily migrate their VMWare vSphere to Red Hat OpenShift after a bit of planning and preparation. And for those enterprises looking for help, Red Hat Services or Global System Integrators are at the ready to assist.
And once migrated, Veeam has your back with a future-proof and enterprise-grade data protection solution.